

https://paulbutler.org/2025/smuggling-arbitrary-data-through-an-emoji/
写了个python版本,感觉有人是会拿来比赛出题的。
Unicode 码点
Unicode 是计算机科学领域的一项业界标准,包括字符集和编码方案。它为每种语言中的每个字符设定了统一且唯一的二进制编码,通常用两个字节表示一个字符。Unicode 码点(Code Point)是指 Unicode 字符在 Unicode 字符集中的唯一编号。
Unicode 编码格式
Unicode 编码格式有多种,其中最常见的是 UTF-8 和 UTF-16。UTF-8 是一种可变长度的编码方式,根据字符的不同范围使用不同长度的编码。例如:
- 000000-00007F: 0xxxxxxx
- 000080-0007FF: 110xxxxx 10xxxxxx
- 000800-00FFFF: 1110xxxx 10xxxxxx 10xxxxxx
- 010000-10FFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Unicode 定义了 256 个代码点作为“变体选择器”,从 VS-1 到 VS-256。这些变体选择器本身没有可见的显示效果,但用于修改前一个字符的显示方式。例如,代码点 U+0067(字符g)后跟 U+FE01(VS-2)仍然显示为小写g,与单独的g相同。但如果复制并粘贴该字符,变体选择器也会随之携带。
由于 256 足以表示一个字节,这为我们提供了一种在任何其他 unicode 代码点中“隐藏”一个字节数据的方法。
变体选择器
按照Paul Butler的思路,假设要编码字符串 "hello",其 ASCII 码为 [0x68, 0x65, 0x6c, 0x6c, 0x6f]。可以将每个字节映射到一个变体选择器,然后将这些变体选择器附加到一个基字符(如空格或emoji)后面。例如,使用emoji符作为基字符,编码后的字符串可能看起来像一个普通的表情符号,但实际上包含了隐藏的数据。
变体选择器的代码点被分为两段:最初的 16 个在 U+FE00 到 U+FE0F 之间,其余的 240 个在 U+E0100 到 U+E01EF 之间。
要从字节转换为变体选择器,我们可以执行类似以下 Rust 代码的操作:
fn byte_to_variation_selector(byte: u8) -> char {
if byte < 16 {
char::from_u32(0xFE00 + byte as u32).unwrap()
} else {
char::from_u32(0xE0100 + (byte - 16) as u32).unwrap()
}
}然后,要编码一系列字节,我们可以在一个基础字符后面连接多个这样的变体选择器:
fn encode(base: char, bytes: &[u8]) -> String {
let mut result = String::new();
result.push(base);
for byte in bytes {
result.push(byte_to_variation_selector(*byte));
}
result
}为了编码字节 [0x68, 0x65, 0x6c, 0x6c, 0x6f],我们可以运行以下代码:
fn main() {
println!("{}", encode('😊', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));
}输出就是:
😊󠅘󠅕󠅜󠅜󠅟解码
fn variation_selector_to_byte(variation_selector: char) -> Option<u8> {
let variation_selector = variation_selector as u32;
if (0xFE00..=0xFE0F).contains(&variation_selector) {
Some((variation_selector - 0xFE00) as u8)
} else if (0xE0100..=0xE01EF).contains(&variation_selector) {
Some((variation_selector - 0xE0100 + 16) as u8)
} else {
None
}
}
fn decode(variation_selectors: &str) -> Vec<u8> {
let mut result = Vec::new();
for variation_selector in variation_selectors.chars() {
if let Some(byte) = variation_selector_to_byte(variation_selector) {
result.push(byte);
} else if !result.is_empty() {
return result;
}
// note: we ignore non-variation selectors until we have
// encountered the first one, as a way of skipping the "base
// character".
}
result
}使用示例如下:
use std::str::from_utf8;
fn main() {
let result = encode('😊', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]);
println!("{:?}", from_utf8(&decode(&result)).unwrap()); // "hello"
}基字符(如空格或表情符号)不需要一定是emoji符号,任何 Unicode 字符都可以作为基字符。
python示例
encode
将字节(0-255)转换为对应的变体选择器字符,判断字节大小并选择对应的变体选择器范围。将基字符和字节数组进行组合,依次生成编码后的字符串。
def byte_to_variation_selector(byte: int) -> str:
"""Converts a byte to a variation selector character."""
if byte < 16:
return chr(0xFE00 + byte)
else:
return chr(0xE0100 + (byte - 16))
def encode(base: str, bytes: list) -> str:
"""Encodes a base character with a list of bytes as variation selectors."""
result = [base]
for byte in bytes:
result.append(byte_to_variation_selector(byte))
return ''.join(result)
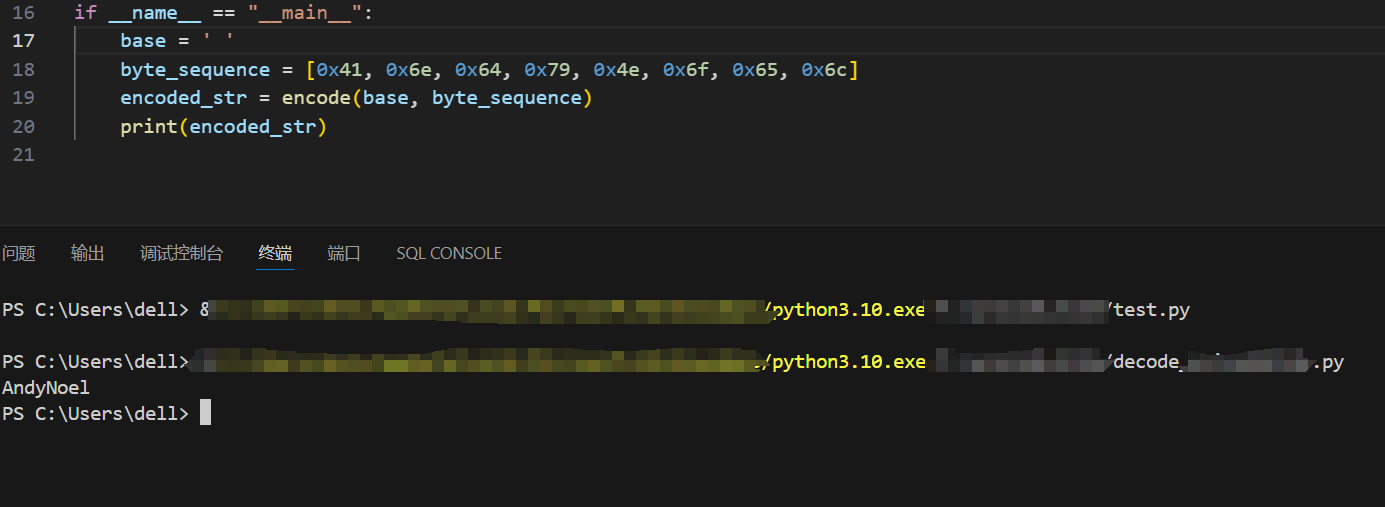
if __name__ == "__main__":
base = ' '
byte_sequence = [0x41, 0x6e, 0x64, 0x79, 0x4e, 0x6f, 0x65, 0x6c]
encoded_str = encode(base, byte_sequence)
print(encoded_str)decode
解密思路就是将每个变体选择器字符映射回其对应的字节值,然后,编写一个函数,遍历输入字符串,提取所有有效的变体选择器字符,并将其转换为字节值。
def variation_selector_to_byte(variation_selector: str) -> int:
code_point = ord(variation_selector)
if 0xFE00 <= code_point <= 0xFE0F:
return code_point - 0xFE00
elif 0xE0100 <= code_point <= 0xE01EF:
return code_point - 0xE0100 + 16
else:
raise ValueError(f"无效的变体选择器字符:{variation_selector}")
def decode(variation_selectors: str) -> bytes:
result = bytearray()
for char in variation_selectors:
try:
byte = variation_selector_to_byte(char)
result.append(byte)
except ValueError:
if result:
break
return bytes(result)
encoded_str = ' 󠄱󠅞󠅔󠅩󠄾󠅟󠅕󠅜'
decoded_bytes = decode(encoded_str)
decoded_str = decoded_bytes.decode('utf-8')
print(decoded_str)